CXL在AI时代已死
 佚名
整合编辑: 王珂玥
发布于:2024-03-18 09:30
佚名
整合编辑: 王珂玥
发布于:2024-03-18 09:30
|
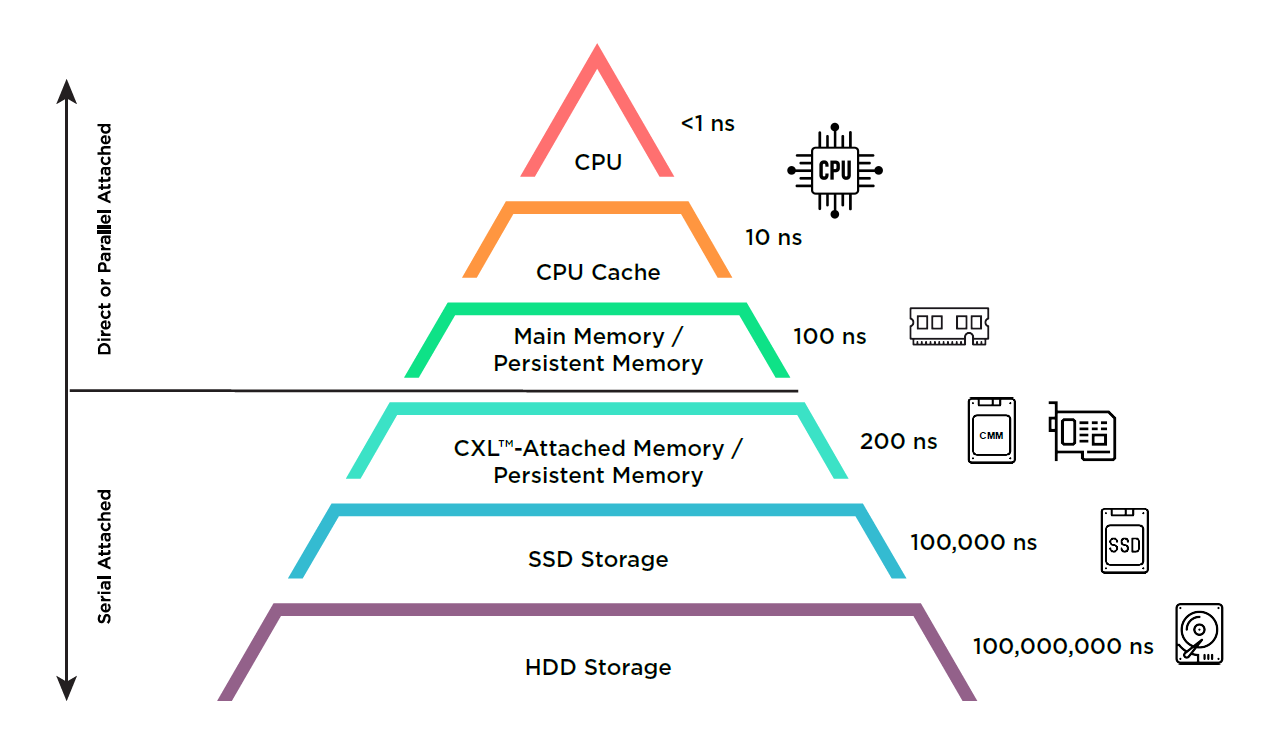
如果我们回到两年前,在人工智能迅速崛起之前,大部分数据中心硬件都在追逐CXL。它被看为是异构计算、内存池和可组合服务器架构的救世主。现有的参与者和全新的初创公司都急于将CXL集成到他们的产品中,或者创建新的基于CXL的产品,如内存扩展器、连接池(pooler)和交换机。然而快进到2023年和2024年初,许多项目被悄悄搁置,许多超大规模企业和大型半导体公司几乎完全退出了市场。 随着即将到来的Astera Labs IPO和产品发布,CXL的讨论至少会在短时间内回到前台。我们已经写了大量关于这项技术的文章,它为云服务提供商以及生态系统和硬件堆栈,提供节省成本的潜力。虽然在纸面上非常有前景,但数据中心的前景已经发生了很大的变化,但有一件事没有改变:CXL硬件(如控制器和交换机)仍然没有大量出货。尽管如此,围绕CXL仍然有很多噪音和研究,行业中的某些专业人士现在将CXL描述为人工智能的“推动者”。 更广泛的CXL市场是否已经准备好起飞并兑现其承诺?CXL能成为AI应用程序的连接点吗?在CPU附加扩展和池化中扮演什么角色?我们将在本报告的订阅部分回答这些问题。 简单的答案是否定的——那些将CXL推向AI的人是完全错误的。让我们首先快速回顾一下CXL的主要用例和承诺。 对CXL的一个简单回顾 CXL是建立在PCIe物理层之上的协议,支持跨设备的缓存和内存一致性。利用PCIe接口的广泛可用性,CXL 允许在各种硬件之间共享内存:CPU、网卡和 DPU、GPU 和其他加速器、SSD 和内存设备。 这支持以下用例: 内存扩展:CXL可以帮助服务器增加内存带宽和容量。 内存池:CXL可以创建内存池,其中内存与CPU分离,从理论上讲,这可以大大提高DRAM利用率。理论上,这可以为每个云服务提供商节省数十亿美元。 异构计算:ASIC比通用CPU要高效得多。CXL可以通过在ASIC和通用计算之间提供低延迟缓存一致互连来帮助实现异构计算,这样应用程序就可以更容易地将它们集成到现有的代码库中。 可组合的服务器体系架构:服务器被分解成不同的组件,并分不同的组,这些资源可以动态地分配给工作负载,从而改善资源搁浅和利用率,同时更好地匹配应用程序需求。 下图说明了部分情况:CXL可以解决主系统内存和存储之间的延迟和带宽差距,从而作为新的内存层。
SNIA 有些人现在预测到2028年CXL的销售额将达到150亿美元,而不是今天的数百万美元,所以我们觉得是时候对CXL市场进行适当的更新了,因为这是一个完全荒谬的说法。让我们从解决用于人工智能的CXL案例开始。 CXL不会成为人工智能时代的互联技术 目前,CXL可用性是主要问题,因为Nvidia GPU不支持,而AMD的技术仅限于MI300A。虽然MI300X理论上可以在硬件中支持CXL,但它并没有正确地公开。CXL IP的可用性将在未来得到改善,但是存在比可用性更深层的问题,使CXL在加速计算时代变得无关紧要。 两个主要问题与PCIe服务器和海滨或海岸线区域(beachfront or shoreline area)有关。芯片的IO通常必须来自芯片的边缘。下面这张来自Nvidia的图片以卡通的形式展示了H100.中心拥有所有的计算。顶部和底部都100%用于HBM。当我们从H100移动到B100时,HBM的数量增加到8个,需要更多的岸线面积。Nvidia将继续在其 2 芯片封装的整整两侧使用HBM。
Locuza 剩下的两边专用于其他芯片到芯片的IO,这就是标准和专有互连争夺芯片面积的地方。H100 GPU有PCIe、NVlink、C2C (Grace)三种IO格式。Nvidia决定只包括最少16个PCIe通道,因为Nvidia更喜欢后者的NVLink和C2C。请注意,服务器CPU,如AMD的Genoa,最高可达128通道的PCIe。 这种选择的主要原因是带宽。16通道PCIe接口的单方向带宽为64GB/s。Nvidia的NVlink为其他GPU提供了450 GB/s的双向带宽,大约高出7倍。Nvidia 的C2C也能为Grace CPU带来每秒450GB/s的双向带宽。公平地说,Nvidia为NVLink贡献了更多的海滨面积,因此我们需要将芯片面积纳入其中;但即便如此,我们估计,在各种各样的SOC中,每平方毫米,以太网风格的SerDes(如Nvidia NVLink, Google ICI等)每单位海岸线面积的带宽要多3倍。 因此,如果你是一个带宽受限的芯片设计师,当你选择使用PCIe 5.0而不是112G以太网风格的SerDes时,你的芯片大约会差3倍。这种差距在采用224G SerDes的下一代GPU和AI加速器中仍然存在,与PCIe 6.0 / CXL 3.0保持3倍的差距。我们生活在一个有限的世界里,放弃IO效率是一种疯狂的权衡。 AI集群的主要扩展和扩展互连将是专有协议,如Nvidia NVlink和Google ICI,或以太网和Infiniband。这是由于内在的PCIe SerDes限制,即使在扩展格式。由于延迟目标不同,PCIe和以太网serde具有显著不同的误码率(BER)要求。
Astera Labs PCIe 6要求的误码率< 1e-12.而以太网要求的误码率为1e-4.这8个数量级的巨大差异是由于PCIe严格的延迟要求,需要非常轻的前向纠错(FEC)方案。FEC在发射器上以数字方式添加冗余奇偶校验位/信息,接收器使用它来检测和纠正错误(位翻转),就像内存系统中的ECC一样。较重的fec增加了更多的开销,占用了可以用于数据位的空间。更重要的是,fec在接收器上增加了大量的延迟。这就是为什么PCIe在第6代之前避免了任何FEC。
Wikipedia 以太网风格的SerDes受严格的PCIe规范的限制要少得多,从而使其速度更快,带宽更高。因此,NVlink具有更高的延迟,但这在大规模并行工作负载的AI世界中并不重要,其中~100ns vs ~30ns不值得考虑。 MI300 AID将其大部分海滨区域用于PCIe服务器而不是以太网风格的服务器。虽然这给了AMD在IFIS、CXL和PCIe连接方面更多的可配置性,但它的结果是总IO大约是以太网风格SerDes的1/3.如果AMD想要与英伟达的B100竞争,他们需要立即放弃使用pcie风格的SerDes。我们相信MI400是这样的。 长期来看,AMD缺乏高质量的芯片严重限制了他们产品的竞争力。他们提出了Open xGMI / Open Infinity Fabric / Accelerated Fabric Link,因为CXL不是人工智能的合适协议。虽然它主要基于PCIe,但出于上市时间、性能、一致性和覆盖范围的原因,它确实避开了PCIe 7.0和CXL的一些标准特性。
原文《CXL Is Dead In The AI Era》 by/ DYLAN PATEL AND JEREMIE ELIAHOU ONTIVEROS |


原创栏目

 硬件编年史
硬件编年史


企业视频

IT百科

网友评论
聚超值•精选
-

- 国家图书馆 西湖全景图鼠标垫文创办公学习用品男女生实用礼物礼品
- 券后省3
-
¥57.0
¥60.0

- 索尼(SONY)索尼(Sony)a7m4 全画幅微单相机 ILCE-7M4//A7M4 A7M4单机身 官方标配
- 券后省100
-
¥14700.0
¥14800.0

- 中国联通 手机卡流量卡上网卡校园卡学生全国通用不限速5G奶牛卡沃派宝卡王卡大萌卡 惠亲卡10包13G全国流量+100分钟通话
- 券后省4
-
¥1.01
¥5.0

- 东芝(TOSHIBA) 移动硬盘 高速 便携外置机械存储 兼容连接MAC电脑 OTG手机大容量硬盘 A5旗舰款 +硬盘包+TpyeC转接头 4TB
- 送赠品
-
¥744.0
¥749.0

- 索尼PS5 Slim轻薄款 光驱版/数字版 家用游戏机 全新 顺丰包邮
- 券后省438
-
¥2778.0
¥3366.0
-

- 腹灵CMK87 87键有线/2.4G无线/蓝牙三模客制化机械键盘热插拔游戏办公RGB灯光PBT键帽 三模FSA球帽-全键可换轴-极夜黑 凯华BOX红轴
- 券后省20
-
¥619.0
¥639.0

- 西部数据(WD)1TB NVMe 移动固态硬盘(PSSD)P40 type-c 游戏硬盘ssd外接xbox手机笔记本拓展存储2000MB/s
- 券后省10
-
¥889.0
¥899.0

- 中国联通 流量卡不限速全国通用手机卡5G上网卡奶牛长期套餐校园卡大王卡新宝卡萌卡 联通惠轩卡19包135G全国通用流量100分钟通话
- 满5减1
-
¥1.01
¥5.0

- AMD 锐龙 CPU 台式机处理器 R7 5700X3D 散片CPU
- 券后省30
-
¥1519.0
¥1549.0

- HKC 27英寸2K 170hz高刷曲面1500R网咖电竞吃鸡游戏三面微边框屏幕显示器SG27QC
- 券后省30
-
¥1169.0
¥1199.0
-

- 雷神(ThundeRobot)X3电竞路由器满血WIFI6 千兆无线路由器 5G双频 Mesh 3000M无线速率 5根天线 游戏穿墙王
- 券后省10
-
¥219.0
¥229.0

- 小天才电话手表Q2A 室内外精准定位视频通话长续航儿童男女孩礼物玩具 Q2A 星云粉
- 券后省100
-
¥499.0
¥599.0

- Apple/苹果2023款Mac mini迷你主机【教育优惠】M2(8+10核)8G 256G 台式电脑主机MMFJ3CH/A
- 券后省400
-
¥3299.0
¥3699.0

- Apple/苹果 iPad mini(第 6 代)8.3英寸平板电脑 2021款(64GB WLAN版/MK7P3CH/A)星光色
- 券后省200
-
¥3799.0
¥3999.0

- vivo X100 Pro 12GB+256GB 落日橙 蔡司APO超级长焦 蓝晶×天玑9300 5400mAh蓝海电池 自研芯片V3 手机
- 券后省50
-
¥4949.0
¥4999.0
-

- ThinkPad联想 ThinkBook16+ 英特尔酷睿i5 新款 16英寸酷睿学生高端商务办公游戏笔记本电脑 i5-12500H 16G内存 2.5K高清屏 512 固态硬盘 标配
- 券后省300
-
¥4699.0
¥4999.0

- PANDA熊猫27英寸Fast IPS小金刚180Hz电竞显示屏1msGTG响应HDR高清133%广色域游戏台式笔记本电脑显示器 FastIPS 180Hz电竞显示屏 S27F18
- 券后省50
-
¥849.0
¥899.0

- 轻磁 MFi认证真液态硅胶快充数据线适用于苹果L口快充 安卓华为小米TypeC 60W 3A充电线 【梧枝绿】C转L【MFi认证】1米 PD60W快充线
- 券后省10
-
¥68.0
¥78.0

- 绿联hdmi切换器三进一出音视频电脑信号笔记本投影仪电视屏幕高清4k分屏显示器3/5进1出一分二分配器五进一出
- 券后省3
-
¥66.0
¥69.0

- 闪迪(SanDisk)4TB Nvme移动固态硬盘(PSSD)E81至尊超极速Pro版SSD 读速2000MB/s手机笔记本外接 三防保护
- 券后省20
-
¥2679.0
¥2699.0















