VMware Private AI ������������VMware Private AI Foundation with NVIDIA
 ���֣����룩
���ϱ༭������h
�����ڣ�2024-04-16 09:01
���֣����룩
���ϱ༭������h
�����ڣ�2024-04-16 09:01
|
���ı���ΪVMware�й�����ܹ�ʦ���֣�����2024��2��21��VMware by Broadcom �� Tech Field Day ��ֳ�AI Field Day 4�����ϵ���ݽ��������ݽ��α�ΪJustin Murray��Product Marketing Engineer, VMware By Broadcom��
VMware Private AI Foundation with NVIDIA��һ��רע��Ϊ��ҵ�ṩ��˽����ȫ�Ϳ���Ϊ�ص������ʽAIӦ�ó����������� ƽ̨������VMware Cloud Foundation֮�ϣ��ر����AI�������Ż������䱸��NVIDIA NeMo���ڶ��ƺͲ�������ʽAIģ�͡� ������AI���ߣ�����ҵ�ܹ�����ģ�Ͳ������ݸ�����������ʽAIӦ�ó���ͬʱ�������ҵ��������˽����ȫ�Ϳ��Ʒ��������ٵ���ս�� ��϶��ƿ�ܡ��������߰�������ɸѡ���ߺ�Ԥѵ��ģ�ͣ�Ϊ��ҵ�ṩ�˼����ø�Ч�ҿ��ٲ�������ʽAI��;���� Ϊ���ݿ�ѧ���ṩ��ݷ��ʹ��ߵ���������Ŀ¼����vCenter�����м��GPU�Ĺ��ܣ��Լ�Ԥװ�����ݿ�ѧ���߰������ѧϰ������� �������ݿ⣬�ر���PGVector������RAG������Ҫ��RAG�����ݿ⼼���������ģ�����ϣ����ṩ���º�˽�ܵIJ�ѯ��Ӧ���ý�����������Ŀ���������ݿ�ѧ�Һ�Ϊ���Ƿ���Ĺ���Ա��������ʹ�ã��ص����ڼ�AIӦ�ó���IJ���������̡� �ý������������������ݿ���ݣ��ܹ���˽������һ��ʹ�ã��������������е���ҵ��Ŀǰȫ�����г���60�ҿͻ��ڲ�Ʒ��ʽ����ǰ�����ּܹ���ʾ��Ũ�����Ȥ�� �ݽ����� VMware Private AI Foundation with NVIDIA��һ��ȫ�漯�ɵĽ�������������NVIDIA������ʽAI�������������ٹ��ܣ�������VMware Cloud Foundation֮�ϣ����ر����AI�������Ż���
����ܹ���� ����ܹ����¿ɷ�Ϊ�ĸ���Ρ��ڶ����ǿ�ѡ���ģ�ͣ����ڵײ�������Ӳ����Ӧ���Ѿ�Ͷ����Դ��ΪNVIDIA AI Enterprise��д�˲���ָ�ϣ���NVAIE��������������Ѿ����������ꡣPrivate AI Foundation with NVIDIA�����VMware Cloud Foundation���������ر���Դ�ģ�ͺ�����ʽAI���������˽�һ�����Ż��Ͳ��䡣 ���У���ɫ����VMware�ṩ�ģ�ר��Ϊ��ģ�ͺ�����ʽAI��Ƶĸ���VCF��չ�������һ��������ѧϰ��������������ݿ�PGVector(����RAG�ĺ���)����������Ŀ¼�ȹؼ��������������Ŀ¼�Ƿ�������꣬�������ݿ�ѧ���ܹ��Լ���ķ�ʽ�����������ǵĹ��ߺ�ƽ̨�����赣���������̿ռ䡣���빫�����ṩ��LLM���ƣ�Ҳ������Ϊ֮����ơ����⣬��ɫ�㻹�ṩ��GPU��ع��ܣ�ͨ��vCenter���棬����Ա����ʵʱ�鿴���ݿ�ѧ���Ƿ�����ʹ��GPU���Լ������Ƿ�������Ҫ�����Ƶ�GPU��Դ�� ����ɫ��֮������ɫ��NVIDIA�㡣��������NVIDIA�ڶ�AI��ش��²�Ʒ����Triton�������������ڽ�ģ�Ͳ�����������������һ�����̡߳���ģ�͵�Ӧ�÷�������ÿ��GPU����һ����ͨ��gRPC API���֡�GPU����Ա���漰��Щ������������Kubernetes�����������������Ҫ�Ľ�ɫ��������������ʱ��NeMo��ܽ����ӹؼ����á��������Ǻ��ģ�TransformerҲ�����е�һ���֡�TensorRT��Ϊģ�͵��Ż����������ܹ���ģ�ʹ�32λ����8λ���Ա������������и���Ч�����С� VMware Private AI Foundation with NVIDIA�뿪Դ����ģ�ͼ��ݣ�����ʾ�лῴ����δ�Meta����Llama 2ģ�ͣ�NVIDIAҲ�������Լ��Ĵ�����ģ�ͣ���߶�ģ�� Megatron������һЩ��������ض���GPU�����˶��ơ��������ʾ�У�����ʹ������һ��ģ�͡�
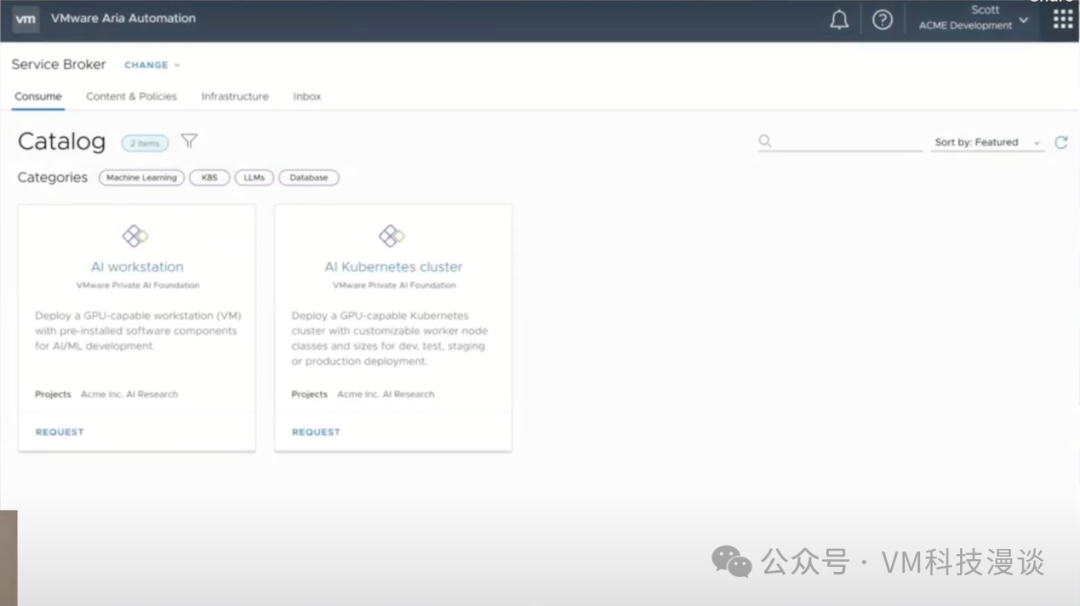
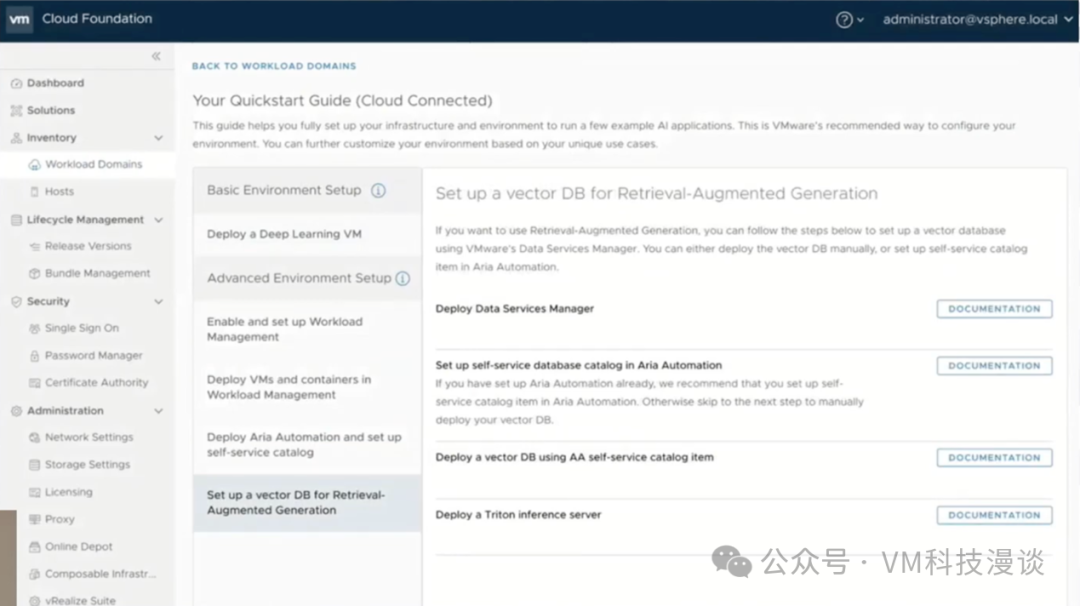
���ڵ�Ŀ����Ϊ���ݿ�ѧ���ṩһ���Ѻõ��û����棬��Ҳ�Ǹý����������Ҫ����֮һ������������Ŀ���û�Ⱥ�壬һ�������ݿ�ѧ�ұ�������һ����Ϊ���ݿ�ѧ���ṩ�������Ա��Ҳ������Ӫ���ƽ̨���Ŷӡ������������Ҳ���ǵ������������������������Ŀ¼��֧��ͼ���û�����(GUI)��Ҳ�ṩAPI�ӿڷ��ʣ����ҿ�������API���м��ɣ�����DevOps��Ա����ʹ��API������������һ�����dz�Ϊ�����ѽ���(CCI��Cloud Consumption Interface)��K8s��Ⱥ�� ���ݿ�ѧ��ϣ���������̾����ܼ����ǻ�����Լ�����������ѡ�������ǿ���ϣ��ֻ��Ҫһ������������������������ǿ�����Ҫһ��������K8s��Ⱥ��֧�����ǵĹ�����
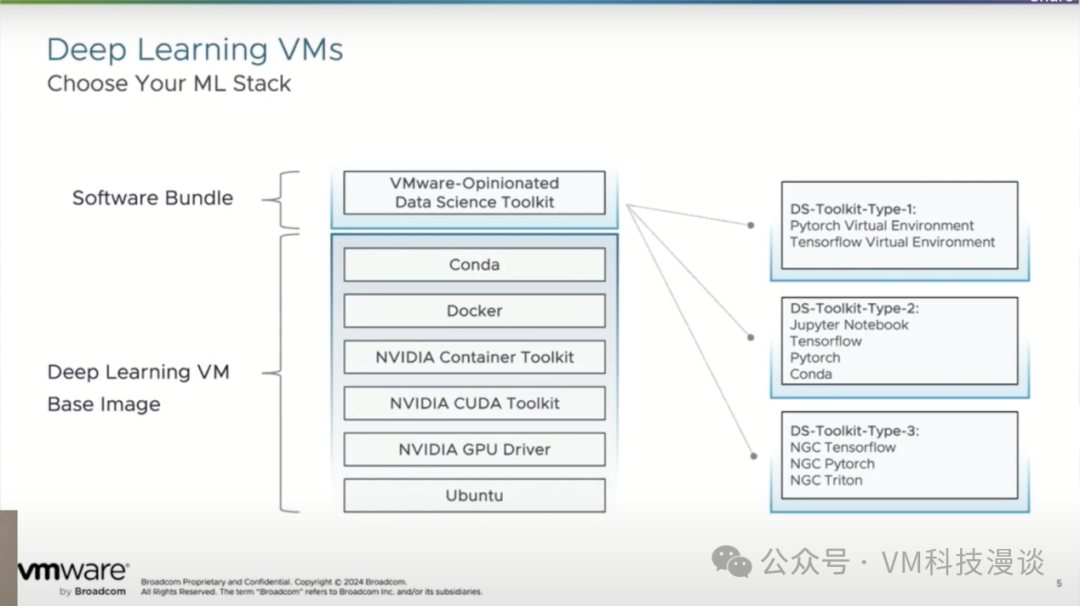
����Щ������ʩ�����ṩ��һ�����ѧϰ���������Щ�������OVA��ʽ���ַ���OVA�ǿ������⻯�ܹ�(Open Virtualization Architecture)����д������һ�����ڷַ�������ı�������ơ���ˣ���Ϊ��NVIDIA������Private AI Foundation��һ���֣��û������յ������ṩ��һ��������� ��Щ�������Ԥװ�˸������ݿ�ѧ��صĹ��߰����������ܻ�ӭ��TensorFlow��PyTorch���������ݿ�ѧ����˵��Jupyter Notebook�ѳ�Ϊ�������ݿ�ѧ�����ı��䣬�ر��ǽ����Python��Jupyter Notebook������ѡ��ʹ��Conda��Docker����������⻯��ֻ�����е�������������ͨ��K8s��������������� ֵ��һ����ǣ�VMware�ṩ��һЩԤ�Ƶġ������Ż������ѧϰ����������û��������ɵش���������Ͷ��ʹ�á���Щ��������VMware��ȫ��Ŀ¼�н������ͣ����������ά�������¼����������������DZ����ڴ洢�ֿ��й��û���ȡ��
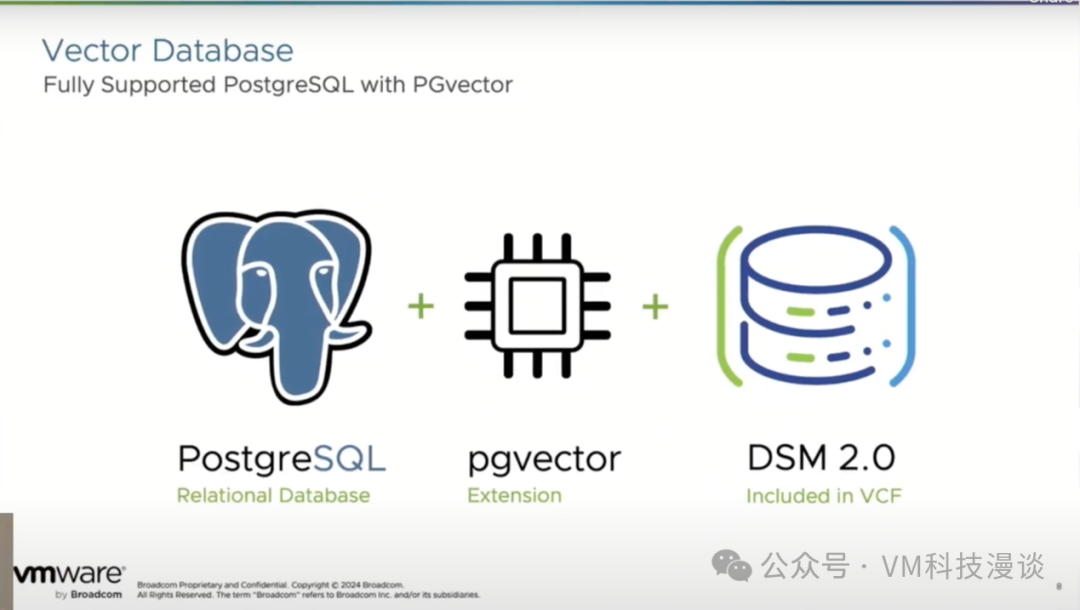
�������������������ݿ⣬���Ǽ�����ǿ����(RAG)�����ĺ�����ɲ��֡��������������ݿⲿ��ʵ�֣�����ǿ��������ģ�Ͳ��֡�����Эͬ�������Ը��õػش��û������⡣RAG�ڴ����������ʱ�dz���Ч����Ϊһ�������������ж���ʵ�ַ�ʽ����P-Tuning(Prompt Tuning)������ģ��Ӧ�ö�������ݡ��������ݿ��RAG��չ�ֳ��������ƣ��Լ����ǴӲ�ͬ��Ϣ��Դ�����ķ�������ʹ���dz�Ϊ����LLM������������ŷ�ʽ��
��ʵ�ʲ����У��û�ͨ��һ���ͻ���Ӧ�ã�����������ˣ��������⡣������ⱻת��Ϊһ����ʾ���������ʾ����ֱ�Ӵ��䵽���ݿ�������ط�����ʾ��һ�����ӣ��ᱻ�ֽ�ɵ��ʣ�������̳�Ϊ��ǻ�����Щ������ת������ֵ����Ƕ��ʽ��ֵ��������Щ���������Ҳ��Ƕ��ʽģ����ɣ��������û������Ⲣ����ת������ֵ����Щ��ֵ����䵽�������ݿ⡣ �û���˽���ļ�������Ҳ���Լ��ص��������ݿ⣬�⽫�漰Ƕ��ʽģ�ͣ���Щ˽���ļ������ݿ�������Ӣ���HTML��д�ģ����ǽ���ǰ���ص����ݿ��С����ԣ����û����Ͳ�ѯ�������ݿ⣬Ҫ���ṩ������δ������vSphere 8 Update 3��������Ϣʱ����Щ�ͻ�������˽�����ݡ��������ݿ��ܹ����������������������ж��û���vSphere 8 Update 3����Ȥ��������������Ƿ�����������������ļ�����Ȼ���ڲ������Ѿ���ǰ���ص����ݿ��У��������Ὣ����ĵ����ظ��ͻ���Ӧ�ó��ͻ���Ӧ�ó���Ὣ��Щ�ĵ�����������ģ�ͽ��л��ܣ�Ȼ�����ݿ�Ľ�������͵�������ģ���д�����������һ�������ܽᡣ ���������ڿͻ��������ģ��пͻ���绰��ѯ�ʣ���vSphere 8 Update 3����Щ����?�������Աߵ�ͬ�¶Դ�һ����֪����ʱ��������LLM�ʣ���vSphere 8 Update 3����Щ����?��(ʵ����vSphere 8 Update 3�Ǽ����º��һ���汾)��ģ�ͻ��Ӧ���������������б�������һ���ܶ��ڿͻ�����������˵�dz��ؼ�����Ϊ���ܰ�������ͻ������ϻ�����ģ�����Ҳ����𰸵����⡣ ���ڴ�����ҵ����LLM��˵������һ���dz��ؼ��Ĺ��̡��Խ��ڷ���˾Ϊ��������ù�˾ӵ��һ��LLM�����ҹ����Ŷ���Ҫ��ͻ����棬������һģ�ͣ���˾����Ϊÿ���ͻ��������ص����ݿ��RAGʵ�����������ݿ⣬������ÿ���ͻ����ض��������ģ�͡���ˣ����ͻ��������������ǰ�����ʷ���̣�������X��Y��Zȥ�����ҵ�˰�ո������Ƕ���?������������ʱ����˾�ܹ��Էdz�˽�ܺ��Ի��ķ�ʽΪ�����ṩ�𰸣��������ܽ���һ̨�ʼDZ���������ɣ�����Ҫȡ����ģ�ͺͲ����Ĵ�С������һ�£�һ���������ʹ�����ǽ��ڻ����ṩ��˽�˱��棬��Щ�ǹ���������ص����ݿ��У�����Ϊ�ͻ��ṩ����ԵĽ������һ������ǰ�����뷨�� ������������ʾһ����Դ���������ݿ⡣�����������ݿ�����VMware��һ���ض��IJ�Ʒ��ǡ��Ϊ�û��ṩ��һ�������ķ������Ǿ���PGVector�� ��Ҫǿ�����ǣ�������ּ����������ݿ⣬����ϼ��ܺͻ��ڽ�ɫ�ķ��ʿ��ƣ��ǽ���Ϊ���롣��Ϊ��������˽�����ݣ���˽�����б��棬��Щ�������ⲿ�������Dz��ɼ��ġ�
VMware����PostgreSQL����������һ���Ѿ߱����ܺͻ��ڽ�ɫ�ķ��ʿ��ƹ��ܵ����ݿ⡣�������û�����ȷ�����ݵİ�ȫ�ԡ�VMware���������������һ�㣬��PGVector��Ϊһ�������������ͨ��Docker��K8s�������������ӵ�PostgreSQL���ṩ�����ӿڡ���������ӿ����������������� ���磬���û�������vSphere 8 Update 3��ʱ������Ϊ��չʾ��֮���Ƶ��ĵ����û�����ʹ��VMware Cloud Foundation�е����ݷ�����������߽������á�������һ���Ѿ����úõ�PostgreSQL���ݿ⣬�����ݿ���������PGVector�������ӣ����ƻ������������ݿ⡣ֵ��һ����ǣ�������߲�������ΪPostgreSQL�ṩ���ã����������ڶ��ֲ�ͬ�����ݿ⡣
���ƽ������У����ٵ�һ�������ǹ���˽�������빫������֮���ת�������磬����ƻ�����һ���ƹ����û�������Ҫ��˽�������Ͻ��д�����ֱ�����ݿ��Թ���Ϊֹ����ʱ���û�ֻ��������ѯ��䣬�硰��ʾ���м������������Ƴ����ĵ�����ϵͳ����Զ�չʾ��ؽ�����������������⽫����ط����û��Ĺ�����������ȫ���еġ����ұߵĴ�����ģ��������֮���������������ݿ⣬����Ϊ��ģ��������������ǰѵ���ģ���˲�δ�������µ�˽�����ݡ����ڣ������ں�̨����ѵ����ģ�͵�һ���°汾����ʹ�ü������������ݽ���ѵ�������ƹ���ǰһ�죬����ģ��Ͷ�����������б�Ҫ�IJ��ԡ�����������������RAG���ݿ⣬��Ϊģ���Ѿ�����������״̬�� Ȼ����ֵ��ע����ǣ�ģ�ͻ���ʱ�����ʱ�����ַ������������ڣ�һ���棬���ݺ��������ݿ������ʼ�ձ�������;��һ���棬ģ��ʼ�ձ��ֻ�Ծ���������������������Ĵʻ㣬ͬʱȷ�����ݵ�˽���ԡ� ��ǰ��ȫ�����г���60�ҿͻ���ʹ�����������������δ��ʽ��������ȷʵ��һ���൱����г����������˸�����ҵ�������Ӧ�ó�����ͨ����������ӿڵ�RAG����˽�����ݡ�������ǿ�ʼ�ĶԻ��dz��а����� VMware SDDC Manager VMware���ṩһϵ��ָ�����飬���а���VMware Cloud Foundation�е�SDDC Manager��SDDC��������һ�����˾�η�Ĺ��ߣ���Ϊ���漰������������ǧ̨�����������������ҵʹ������������VMware�����������г�Ӫ��������������ҵ���ܹ���������ȡ���Ҳ��VMware�����û�����ʱ������ע��һ���㡣
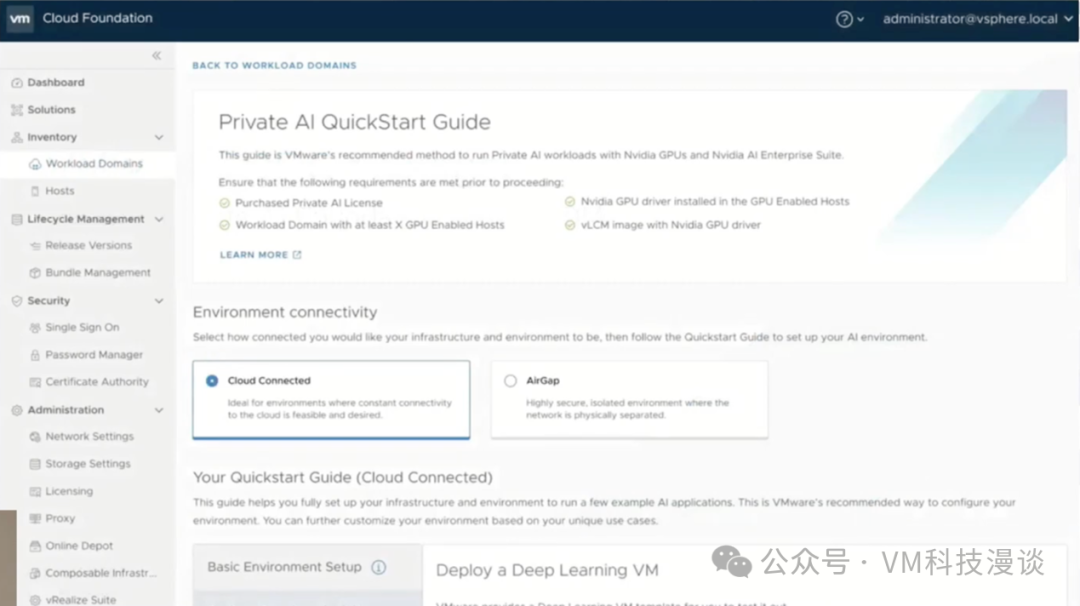
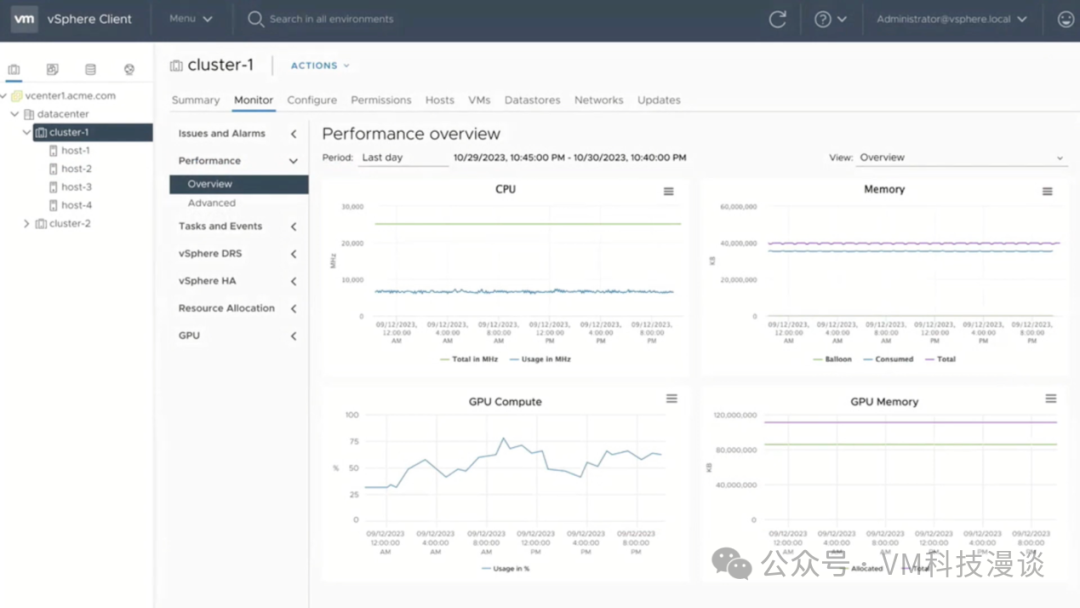
VMware���ṩ����ָ�ϡ��û��ֲ�Ϳ�������ָ�ϣ���ָ�����ִ��ǰ���ᵽ�����в��裬���粿�����ѧϰ���������������ݿ�ȡ�ͬʱ�����߱���Ҳ���ṩ����IJ���ָ�ϡ� GPU��� ���һ�����⡪��GPU��ء�VMware�Ѿ����������ݿ�ѧ�ҵ�����Ϊ�����ṩ������Ĺ��ߺ�ƽ̨�����ǽ�����ģ�ͣ�������ʹ����Щģ�ͽ���������
������Ҫչʾ���ǣ����������ȼ��б��У�����CPU���ĺ��ڴ������⣬���ڻ�����GPU�������ĺ�GPU�ڴ����ġ���Ϊ��Щ�豸�ɱ��߰����ر��Ǹ߶˵�H100�豸������ϣ��ȷ����Щ�豸�õ�������á�
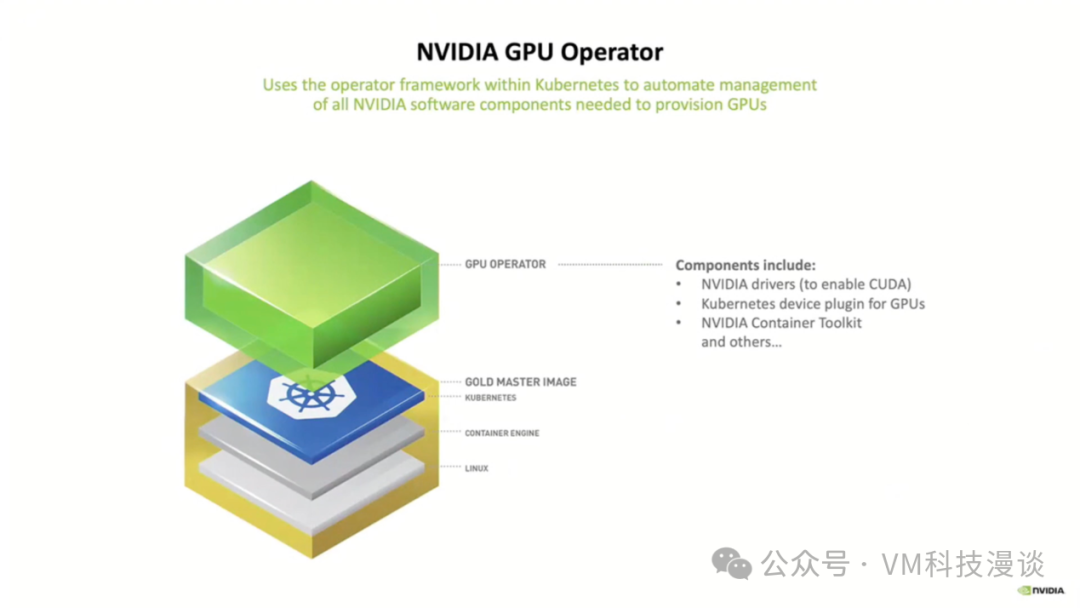
�ڴ�֮ǰ���ȼ�Ҫ����һ��NVIDIA��һЩ�����GPU Operator�Ѿ����ںü����ˣ�������߷dz���ɫ����Ϊ��ʹ��NVIDIAջʱ���û���Ҫ����������������һ��������������ESXi����һ������������������GPU��ÿ�������������K8s�����У�GPU Operator��ӹ���Щ��������Ĺ��������Ḻ��װ�ͻ������������佡��״��������K8s��Pod�����У�ֻ������������û���Ҫ��K8s��Ⱥ���Լ���Ҫ��GPU��Ȼ�����ᴦ��ʣ�µ����飬�⼫��ؼ����û��Ĺ����������������û��Ͳ���Ҫ�ٽ���������װ���ͻ�����ϵͳ���ˡ�
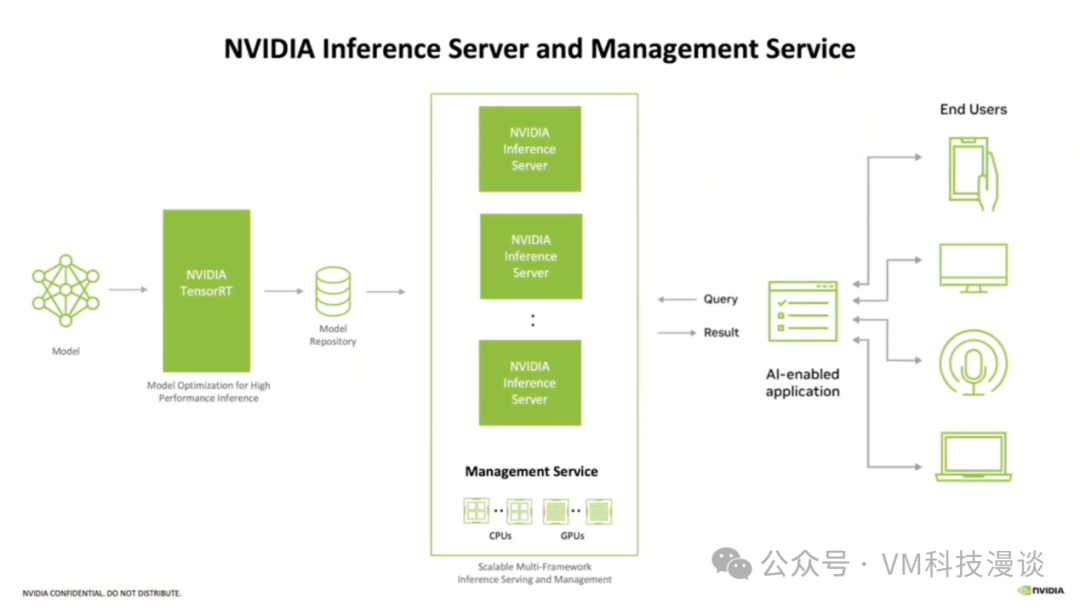
����ʱ��������ѵ��ʱ��Ļر�����Ͷ�ʣ��Ƿ�չ��������ʱ������������������ϣ�������ǿ���չ�ģ���NVIDIA��Triton��������������Ϊ�˶���Ƶġ����磬��������GPU��������������ÿ��GPU�Ϸ�����һ��Triton����������������ģ�������ģ���һ��dz���Ҫ����Ϊ��ϣ����һ��������ͬ�汾����ͬ���ݼ���ģ�Ϳ⣬����������һ��ģ�͡�����֯�У����ܻ�����ʮ�������ٸ�ģ�ͣ��û���Ҫ����Щģ�ͽ��п��ơ�MLOps��Ӧ�̻ᴦ����Щ����������Ҫһ���洢�⡣NVIDIA�����ﴴ����һ���߶ȿ���չ����������������ӵ��API�ӿڣ��û�����ͨ��API��ͻ���Ӧ�ó���������ǵ�ģ�͡��ͻ���Ӧ�ó���λ���Ҳ࣬���Dz����ѯ��������⣬�ʵ�����������������ղ�������Щ���⣬�������û�ȥִ��ģ�͡� �������β�ȡ���ƴ�ʩ��ʵ���ϣ�NVIDIA�ṩ��һϵ�еļ����ֶ�������ʵʩ��Щ��ʩ����Щ����������Ч��Ԥ��ƫ�������ںܴ�̶��Ͻ��ƫ�����⡣���⣬���ǻ��ܹ���Ⲣ�ų��ܾ�������ȷ��ģ�͵İ�ȫ���ݡ�NVIDIA�ṩ��һϵ�����ʵ���ͼ���֧�֣�Ϊ�û���ģ���ṩȫ��λ�ı����� VMware AI������������Ϣ���� Artificial Intelligence Solutions | VMware AI: https://www.vmware.com/artificial-intelligence.html VMware's Approach to Private AI: https://news.vmware.com/technologies/vmware-technology-private-ai Deploying Enterprise-Ready Generative AI on VMware Private AI: https://core.vmware.com/resource/deploying-enterprise-ready-generative-ai-vmware-vmware-cloud-foundation |









ԭ����Ŀ

 Ӳ������ʷ
Ӳ������ʷ


��ҵ��Ƶ

IT�ٿ�

��������
�۳�ֵ•��ѡ
-

- ��Ѷ (PowerColor) RX6650XT ���� AMD̨ʽ��Ϸ�Կ��羺����RX6600 8G�Դ� ��RX6600 ������
- ȯ��ʡ100
-
��1499.0
��1599.0

- �����壨Varmilo�� ��èϵ�л�е���� ������V2���� ���̻�е ��Ϸ���� ����Ա���� ��èMA87���� ������V2���ջ���
- ȯ��ʡ50
-
��869.0
��919.0

- ����(SanDisk) 256GB USB3.2 U��CZ74��������400MB/sȫ������Ʒ��u�̰�ȫ����ѧϰ�칫�������̴�����
- ȯ��ʡ10
-
��149.0
��159.0

- Apple/ƻ�� Watch Ultra2 �����ֱ�GPS+���ѿ�49�����ѽ���������ɫ��ɽ�ػ�ʽ����С��MRFA3CH/A
- ȯ��ʡ400
-
��6099.0
��6499.0

- vivo iQOO Z8 12GB+512GB ��ҹ�� ���� 8200 120W�������� 5000mAh�������� 5G�ֻ�
- ��1000��150
-
��1989.0
��1999.0
-

- �����ι�����PLUS��ɫȫ���溣�������䣨�ֻ������������˿/������/360ˮ��/ATX����/40ϵ�Կ�
-
��219.0
��299.0

- ���ɣ�ViewSonic�� 29Ӣ�������ʾ�� 21:9���������� IPS���ӽ���� HDR���� 75Hz �߿� �����ⲻ���� ���� ����칫��ѡ VA2962-HD
- ȯ��ʡ200
-
��949.0
��1149.0

- BoseQuietComfort ����������������� ����ϵ�д���3�� ���ܶ���������У ���ܻ����� �������� �������II-��ɫ ���й���� ȫ������
- ȯ��ʡ200
-
��1299.0
��1499.0

- Apple/ƻ�� Watch Series 9 �����ֱ�GPS��45����ɫ���������� ����ɫ�ػ�ʽ�˶����� MR9J3CH/A
- ȯ��ʡ400
-
��2749.0
��3149.0

- �����ߣ�EDIFIER�� W820NB˫��� Hi-Res����������� ͷ����ʽ����������ƻ���� ��˫���桿���Ż�+��������
- ȯ��ʡ30
-
��369.0
��399.0
-

- ������С�̶������������߰����ʽ�¿�X1���û�Ϊƻ��С��2024
- ȯ��ʡ17
-
��89.0
��129.0

- �������٣�Harman/Kardon������3�� �������� ������������̨ʽ��������������� ������ Aura Studio3�� ��ɫ
- ȯ��ʡ30
-
��1389.0
��1419.0

- ���ǣ�SAMSUNG��Galaxy Buds2 Pro ��������������������������/24bit�߱�����Ƶ/IPX7��ˮ/������� ����̫��
- ȯ��ʡ10
-
��989.0
��999.0

- Apple/ƻ��2023��Mac mini���������������Żݡ�M2 Pro��10+16�ˣ�16G 512G ̨ʽ��������MNH73CH/A
- ȯ��ʡ300
-
��8899.0
��9199.0

- �����Sƻ��MagSafe����TPU������iPhone��Һ̬�轺CD��ֱ���ֻ����Դ���ͷĤ ����ҹ�ϡ�CD�ƴ����� iPhone 14
- ȯ��ʡ77
-
��129.0
��206.0
-

- ���������߱�·���� AX3000��߸ ���µ�ȫ���WiFi6 5G˫Ƶ ȫ��Mesh���� 3000M�������� ǧ����·����
- ȯ��ʡ6
-
��222.0
��228.0

- Ʒʤ ����ƻ��15�ֻ��� iPhone15������Լ�����ҷ�ˤ����������ĥ����ȫ����ָ���������� ��
- ȯ��ʡ4
-
��25.0
��29.0

- ��̩ ZOTAC ZBOX����mini����EN072060C̨ʽ��2060ͼ���Կ�����վ���ʦ��Ⱦ��Ե�����豸 ϵͳ�������ڴ�Ӳ�̡�
- ȯ��ʡ100
-
��2999.0
��3099.0

- IDMIX ��籦�Դ���ƻ��MFi��֤PD20W���1�����ʱ����ƻ��14/13/12Pro/Max PD20W����Դ�ƻ��MFI��֤��/��ɫ
- ȯ��ʡ40
-
��259.0
��299.0

- С��ƽ��6 MAX 14Ӣ�� ��ͨ����8+ PC��WPS 2.8K 120Hz 8+256GB�칫ƽ����� ��ɫ������+���ر���װ��
- ȯ��ʡ100
-
��4697.0
��4797.0





