VMware Private AI������������VMware �ڲ�Private AIʵ������
 ���֣����룩
���ϱ༭������h
�����ڣ�2024-05-06 10:18
���֣����룩
���ϱ༭������h
�����ڣ�2024-05-06 10:18
|
���ı���ΪVMware�й�����ܹ�ʦ���֣�����2024��2��21��VMware by Broadcom �� Tech Field Day ��ֳ�AI Field Day 4�����ϵ���ݽ��������ݽ��α�ΪRamesh Radhakrishnan��AI Platform & Solutions, VMware By Broadcom��
����ժҪ -VMware�ڲ�AI���������븨������ʹ�ü�����ǿ����(RAG)�����ĵ������ķ����Լ��ڲ���LLM API�ȡ� -VMware�ڲ�LLM�Ĺؼ������������������ɡ�����ش𡢴������ɺ�AI������ʹ�õȡ� -VMware�������Ʋ��ԣ����ù�����ѵ����Դ LLM���Լ��� GPU ���жԻ�����Ӱ�졣 -��˹̹����ѧ������Ϊ�ڲ��ĵ�����������һ����������Ӧģ�ͣ��봫ͳ�Ĺؼ���������ȣ�����������������ܡ� -VMware�Զ��ʴ�ϵͳ(vAQA)��һ����������ģ�͵���Ϣ����ϵͳ���������û��ڲ�����ĵ��������������Ⲣ�õ���ش𰸡���ϵͳ��ʵ���漰���ӵĹ��̣����������ռ���Ԥ��������������������ĵ��� -VMware������GPU������VMware��AIƽ̨�ṩGPU����Դ����������������������LLM API����Щ��������һ������ƽ̨�ϡ� -���ݹ������˹�����������DZ��ƿ����ƽ̨�������ڸ�Ч��Ϊ�ն��û��ṩ����������Ҫ��AI�ŶӺͻ����ܹ��Ŷ�֮���Э������ȷ��ģ�ͺͻ����ܹ��ܹ���Ч֧�ֹ�������������Ҫ�� -��֯�ɴ�С�Ϳ�Դģ�Ϳ�ʼ���������ģ��ȷ���ؼ���Чָ��(KPI)����רע����AI���ҵ�����⡣ǿ��ʵʩ�˹����ܵ�ս�Է�������Ҫ�ԣ��Լ������˹����ܷ�����ƽ̨�ĺô��� �ݽ����� ���ݽ��������VMware�ڲ�Private AI��һЩʵ��������ڴ�����ģ����δ����֮ʱ��VMware�ڲ����Ѿ���������һϵ�е�Ӧ�ó��������Ŵ�����ģ�͵Ŀ��ٷ�չ��VMwareҲ���������������Ϊ�����ŶӴ����˻��ڴ˵�ƽ̨���ܣ�ʹ����Ҳ�ܹ�������ЩӦ�ó��������ⷽ�棬VMware�ܽ���һЩ��Ҫ���ĵ���ᣬ���������ͻ�����VMware�������Ʒ�չ�ε���֯�ܹ����м�ȡ���顣
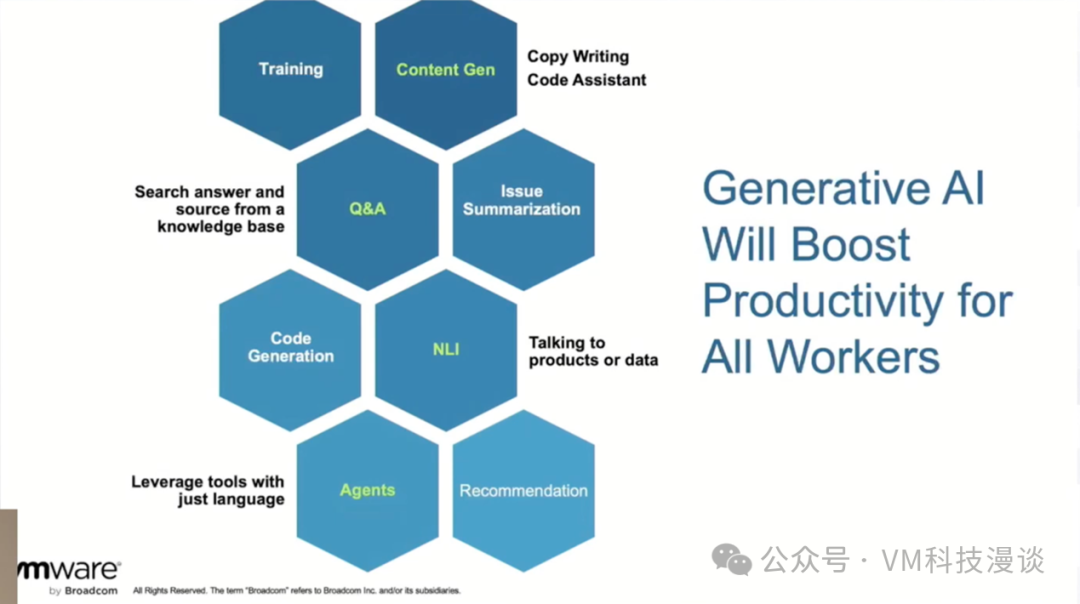
��̽�ָ���Ӧ�ó���ʱ��������ģ�;���һ�Ѵ��ӣ�������Ӧ�ó��������Ƕ��ӡ�������Ϊ������ģ���ܹ��ڼ������ĵ������Ӧ�Ը���Ӧ�ó��������������������ڡ� VMware�ڲ�AIӦ�ó�������ط��� ����һ������Ӧ�ó������������ɡ�������ģ�Ͳ�����ѵ�������ı����ɣ����߱���ģ̬��������ͼ�����Ƶ���ɡ��ܶ��˶�����ע������������Sora���������Ϣ��ը��ʱ����������̸���ʴ�ʱ����Ҷ�ϣ���ܹ�����Ч��������������ģ�Ͳ������ԴӲ�ͬ��Դ��ȡ�𰸣������ۺ���Щ��Դ��Ϊ�����ṩ�𰸣������Ķ�����ĵ��� ���ڴ������ɣ���Ҫ�ٴ�ǿ�����ⲻ���������ڴ�ͳ����Ա��������ʹ����Terraform�ȹ��ߵĹ���Ա����һ�����Ӧ�ó����dz��㷺�� ����ῴ�����������������ʾ�С���Щ���������ö��Ӧ�ó�����������������ӣ�����ͨ����������Ӧ�ó��������������ӵĽ����������ʵ�ָ��м�ֵ��Ŀ�ꡣ�������ķ�չǰ���dz�������δ��������׳�� ����VMware���ڵ�������֯��ϣ����������ʽAI��DZ���������DZ������������ЩӦ�ó������Ŷ������ڴˣ���Ҫ�ٴ�ǿ����VMware��˾�ڲ��ƶ���һ�������ʹ����Щ����ʽAI���������ߣ�Ϊ�Ŷ��ṩ����ȷ��ָ�����롣 VMware�������Ʋ��� VMware��ȡ��һ�ֲ����Dz��������Ƶķ�������ȥ��VMware�Ѿ�̽�ֹ��������ڴ�ͳӦ���е�Ӧ�ã������漰��AIӦ��ʱ������ζ�Ž��������ڹ�������ѵ������Щ������ģ�͡���Щģ�������ǿ�Դ�ģ����䱸����ҵ���ɣ�ʹ�����ܹ����Լ���Ӧ�ó������������ǡ�ͨ���������������Ա����ڲ���Ҫʱ����GPU���Ӷ���ʡ������̼�ŷŲ����ٶԻ�����Ӱ�졣
һ����Щ������ģ���������ǵĻ�����ʩ�����ܹ�����Ӧ���ڶ����������������Ҫ����ģ�͵����ܺ��ӳ١����������ܹ��Էdz��ɳ����ķ�ʽ���в�����ʵ���ϣ���������Ӧ�ó��������Dz�����Ҫ700�ڻ�1000�ڲ�����ģ�͡�һЩ��������ר����ƵĽ�Сģ�;���ʤ�Ρ�
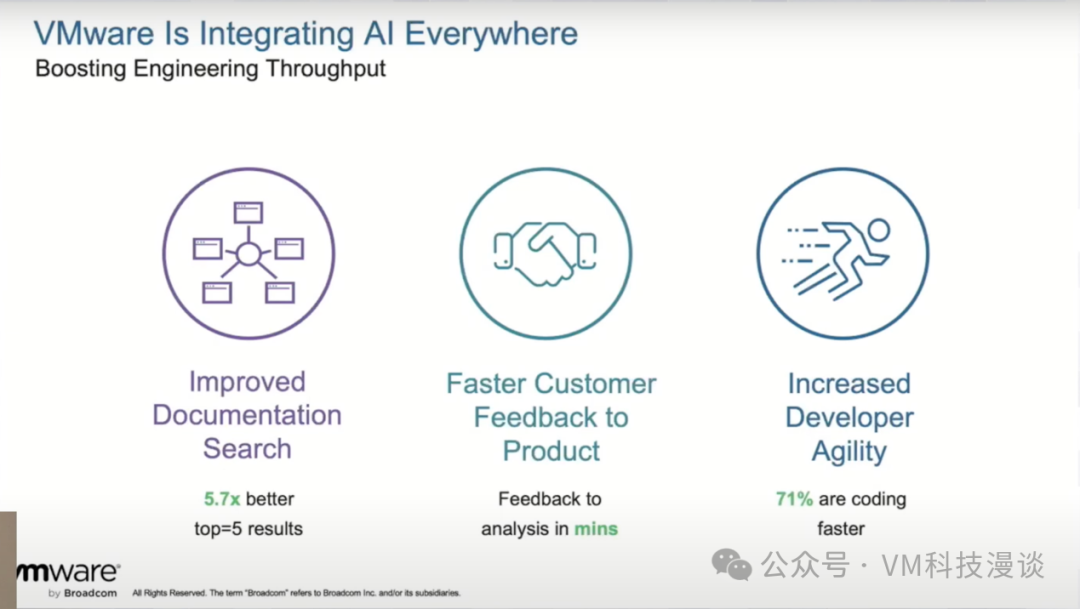
���ƽ���һ����ʱ���������ȿ��ǵ��������ڲ��Ŷӵ�ʵ������һ��Ӧ�ó����ǸĽ��ĵ���������һ�������ʾ�����Լ��40%��ʱ�䶼����Ѱ����Ϣ�ϡ������dz���Ա��Stack Overflow�����������Dz�Ʒ������Google��Ѱ�����ݣ���������ͬ�������⡣��ˣ�������˹̹����ѧ������ΪVMware����������һ����������Ӧģ�ͣ���ģ����ǰ�����������е����ܱȴ�ͳ���������Լ�屶�롣������ؼ���������ȵ�������Ȼ�����ǽ����ģ�����䵽VMware�Ĵʻ�����Ի�ø��������м����Ľ���� Ϊ��ȷ����Ʒ�벻ͬ�汾���ĵ����н����������ȥ���������ƵĶ����vSphere 6/7����ȡ��ƥ���������ʵ����Ҫ��8.0�汾��ƥ�䣬Ϊ��ʹ���������������������������������������������ܹ�ʶ������ʹ�õİ汾�����ݴ���ȡ����ĵ������û����ȷָ���汾��ϵͳ��Ĭ����ȡ���µ���Ϣ������������й���ʹ�ð汾����������Ϣ��ϵͳ�ͻ������Щ��Ϣȥ�ռ����ϣ��Ӷ�������ȷ���ĵ��� ���Dz������ڸĽ��ĵ������������������е��ĵ������⣬���������ĵ�֮�⣬���ǻ����Confluenceҳ����ⲿ��������ȡ��Ϣ����ˣ����ǵ��������ݶ��ᱻ�������������������ԣ����û�����ʱ�����ǵ�ϵͳ�������صĶ������Ϣ������ȡ�����������Ǵ��ĵ����������ⲿ��Դ����Щ�ĵ����������¡��ڲ�KBS�Լ�����������Դ���ڲ��ϵظ��¡� ����ڿ����ߵ�����ԡ��������ǵĵ��飬�������Ա��ϣ����һ���������֡���ˣ�����ϣ���ܹ�Ϊ�����ṩһ���ڲ����еķ����������ǵĴ���Ͷ��ܱ����������Լ��ķ���ǽ���ˡ� VMware�Զ��ʴ�ϵͳ(vAQA)
����������̽��һ���ĵ����������ǵ�ϵͳ����ΪVMware�Զ��ʴ�ϵͳ(vAQA)������������һ�����������ߡ������ֱ�����ʣ�ϵͳ��Ϊ���ṩ��ش𰸡���ˣ��������ٷ�����������ĵ���Ѱ��������Ϣ������֮ǰ�ᵽ�ģ��ĵ������Ӵ������Dz������ӡ� �����������ǹ�����һ����������ģ�͵���Ϣ����ϵͳ����Ȼ���ڵĴ�����ģ�Ϳ���������������Ҫȷ�����ȷ�Ĵ𰸡��ṩ��Ч�ķ�����ʩ����ȷ���������ģ�����Ҫ�����Ĺ��̹�������Լ�������ǰ�����ǿ�ʼ��˹̹����ѧ��������ʱʹ�õ������Ƚ�������ģ��ColBERT������ʱ������ƣ����Ƕ��ʴ�ϵͳ�����˶�θĽ��� �����ϣ�������̿��Է�Ϊ�ĸ����衣���յ���ѯ����ʱ��ϵͳ������������ѯ��Ȼ�����б��������洢�����ݿ��е����ݶ��ᱻ���ݸ�ColBERTģ�͡�ģ�ͻ�����ݿ�����ȡ����ĵ��������䴫�ݸ�����ش�ϵͳ����ϵͳ��ͻ����ʾ��ض��䣬����������ظ��û����������ܼ���?��ʵ���ϣ�Ϊ��ȷ����Խ���Ƚ��Ľ�������ǽ����˴�����ʵ�������
����������ϵͳͶ������ʱ�������ø��Ӹ��ӡ��ո�չʾ�����Ҳ�IJ��֣�������Ϣ������Ԥ�������������ش�ϵͳ�����IJ��֣������ĵ����¡����������Լ����ĵ������仯ʱ�Ĵ������̡� ��������ʼ�������ռ��������ʹ�����ݱ���ϵͳ����DocWorks��������ֱ�����͵����Ͽ⡣�����ǻ�ϣ��ʹ�����������ĵ�����ˣ�������Ҫʹ������������վ��ץȡ��Ϣ����������µ����ݿ��С��Ⲣ�����£���Ϊÿ����վ�Ľṹ�����ݶ�������ͬ����ʹ���������̱���൱���ӡ� һ����ȡ����Щ��Ϣ�����Ǿͻᱻ���͵����ݹ����������ȫ�����������е�������Ϣ��������Ԥ�������罫����ת��Ϊmarkdown��ɾ��������Ϣ�Ȳ��裬����һһ���������⣬Ϊ��Ӧ��ƴд������Ӵʻ㣬������ר�ŵ�Ԥ�����������ǻ���Ҫ���б�ǻ��������Ա㴦���ʻ��֮��ĵ��ʡ���������Щ����������������ɺ���Ϣ�ͻᱻ�͵������������ڡ� �����������У����ǻ�����ռ����������ݴ����µ��������������ճ�����������˵�����ǻ���ȡ������Ϣ���ĵ������Ҹ������ݣ�Ȼ��ݴ˸����������ĵ��� Ϊ�����Ч�ʣ����ǻ��Ի���������Ż������֮ǰ�Ѿ����й�ij�����������һ������������Ϣ����ôϵͳ�������ٴν����������Ӷ�����˴����ٶȡ� �����������У�����Ҳ����GPU���м��㡣���ְ��������ķ�ʽ�������ڲ���Ҫʱ��ʡGPU��Դ�� �����Ѿ��������Ӧ����RAGӦ�ó������Ӷ�������һ���Ի����档������ʹ���˴�����ģ�ͣ���ͨ�������Ż��������������������ڴ˳����£�����û��ʹ���������ݿ⣬����ֱ�ӵ���API����ȡ������Ϣ�����ݴ˻ش����⡣ ��ǰ������֯����Ŭ�������ȡ���������������ݿ�����ܹ�����ս�������ṩ��һЩ��������Ҳ�Ѿ���������صļ�����Ŀǰ�����о���ν����װ�ɸ�ͨ�õķ����Ա����Ŀͻ��ܹ�ʹ�ã������ɵ����ǵ�Private AIϵͳ�С�ͬʱ������Ҳ�����ǵ�רҵ�����ŶӺ��������ݿͻ����ض������ṩ���ƻ��ķ���
����Ӧ�ó������������������ڲ�ΪԱ���������ʴ����֡������������һ��������߱�����
VMware������GPU���� �ڳ��ڣ����ǵ���Ҫ���ںͿͻ������ݿ�ѧ�ң����������û���ѧϰģ�ͽ��ʵ��������ˡ����ǵ�ʱ��ҪһЩGPU��Դ�����ֹ���ʵ��������CPU����ɵġ���ˣ����ǹ��������ƽ̨�������û���������������Դ������Ϊ�����ṩ������Ŀ���������������Jupyter Notebook����Visual Studio�����Ƕ����Կ�ʼ�����Ͳ���ģ�͡� Ȼ��ChatGPT�ij��ֳ��ı�����������ڣ������д���������������Ա��Ҫ����Ӧ�ó������Ƕ�GPU������Ҳ�������ӡ���������ˣ�������Ȼʹ��ͬһ��ƽ̨�����������ֲ�ͬ���͵�Ӧ�ó����� ������������������Ա��˵������ʵ���ϲ���Ҫֱ�ӷ��ʼ��㻷��������������ֻ��ҪAPI�ӿڡ���ˣ����ǹ�����һ���йܷ����������������ģ�ͣ����ṩAPI�ӿڹ�����ʹ�á����dz�������ƽ̨�������¹��ܡ�ͬʱ������Ҳ��Ԥ�⣬������ģ�͵��Ƴ������ǵĿͻ�Ⱥ������µ����� ��������ǵ�ƽ̨��ò�����ǽ�����һ��GPU��Դ�أ�ȷ���κ��û��������ռ��Դ��һ���û����������Դ�ͻ��ͷŻس��С�������ƽ̨�ϲ����˿�������������Ӧ�ó����ʹ�������ģ��API��
���ݹ�������Ҫ�Լ���ҵAIʵ������Ѳ��� ������һ���ؼ����ء��ںܶ�AIӦ�ó����У����ݶ���ƿ������Ȼʱ��ԭ������û������̽����һ�㣬����ȷʵ��ֵ��ע��ĵط���ʹ��ͨ�õ�ģ�ͺͱ�����ƽ̨��������֯���õ��������û��ṩ������������ͬ���ŶӾͲ����ظ����ͬ�������⡣����AI�ŶӺͻ����ܹ��Ŷ���˵��Эͬ����������Ҫ����ʹ������õ�ģ�ͣ������û�к��ʵĻ�����ʩ������չ������ʩ�������������أ���ô��Щģ�ͽ����õ�������á�ͬ���������ӵ�г�ɫ�Ļ�����ʩ����û�������AIģ�ͻ������ôҲ��ʵ�����Ч������ˣ������һЩ��Դģ�Ϳ�ʼ����ȷ���KPI����Ҫ�����ҵ�����⡣������֯��ʼʱ����Ѳ��ԡ���������ǵ�������
Artificial Intelligence Solutions | VMware AI: https://www.vmware.com/artificial-intelligence.html VMware's Approach to Private AI: https://news.vmware.com/technologies/vmware-technology-private-ai Deploying Enterprise-Ready Generative AI on VMware Private AI: https://core.vmware.com/resource/deploying-enterprise-ready-generative-ai-vmware-vmware-cloud-foundation |








ԭ����Ŀ

 Ӳ������ʷ
Ӳ������ʷ


��ҵ��Ƶ

IT�ٿ�

��������
�۳�ֵ•��ѡ
-

- ��е������14X 2024��Ʒ AIPC�����콢����7 8845HS�ᱡ�� 14Ӣ����������ʦ�칫ѧ����Ϸ�ʼDZ����� 120Hz��ˢ 2.8K��ɫ�� ������ R7-8845HS 24G�ڴ�1TB��
- ȯ��ʡ300
-
��5399.0
��5699.0

- ����������ڴ����� ���������� ���ײ��״��Ӧ���ڵƲ��� ������ڴ�����-��װ��
- ȯ��ʡ2
-
��137.0
��139.0

- �������ݣ�WD��1TB SSD��̬Ӳ�� M.2�ӿ� SN770 PCIe4.0 2280��NVMeЭ�飩AI������� �ʼDZ�������ϷӲ��
- ȯ��ʡ30
-
��639.0
��669.0

- ��˳������ҫWiFi6�ڱ��羺·����X30E PROǧ��������AX3000˫Ƶ5G ��Ϸ����ȫ��WiFi���ǹٷ��콢��
- ȯ��ʡ10
-
��289.0
��299.0

- ���������߱� AX3000����Ȩ���·���� ÿ�����Ա ȫ��Mesh���� 3000M�������� Խ����ǽ����
- ÿ��349��100
-
��343.0
��349.0
-

- ����wifi6����ǧ���ù��˸���·���� mesh������ǽ��ȫ����ǿ��
- ȯ��ʡ100
-
��109.0
��209.0

- �건�� ƻ����ʹ�۷��б����Ƿ�ˤ��Һ̬�ָ�TPUֱ���ֻ��� ���ʻơ���ʹ�ۡ������� iPhone 13
- ȯ��ʡ10
-
��17.0
��27.0

- CHINOE-��ŵ2W������������籦22.5W˫�����ƶ���Դ
- ȯ��ʡ100
-
��69.0
��169.0

- ��̩��ZOTAC�� RTX4070 X-GAMIN���� 4070 SUPER�Կ�/N��/̨ʽ��/���Զ����Կ� RTX4070 SUPER 12G ����OC
- ȯ��ʡ200
-
��5799.0
��5999.0

- �����ߣ�EDIFIER�� M30 ����5.3���� ��Ϸ���� �ʼDZ������������̨ʽ������ ������˷� ��ɫ
- ȯ��ʡ16
-
��173.0
��189.0
-

- ��ɳ��Lexar��128GB SD�洢�� U3 V60 4K��������ڴ濨 ��250MB/s д120MB/s ˫�Ž���ָ��1667x Pro��
- ȯ��ʡ10
-
��269.0
��279.0

- ��������(WD) 2TB �ƶ���̬Ӳ�̣�PSSD��Elements SE��Ԫ�� SSD type-c�ӿ� �ֻ�ֱ���ʼDZ��������
- ȯ��ʡ20
-
��949.0
��969.0

- ����(Lenovo)С��һ��̨ʽ������23.8Ӣ��(R5 5500U 8G 512G SSD ����ͷ win11 )��
- ȯ��ʡ10
-
��3089.0
��3099.0

- B&O Beosound A9 5.G 5��һ��ʽ����WiFi���������������� ���ص��� ���� A9 4G ��ɫ
- ȯ��ʡ250
-
��18949.0
��19199.0

- ikbc Z87��ħ�ߴ��ħ�������������̻�е����������Ϸ�칫����87������
- ȯ��ʡ20
-
��219.0
��239.0
-

- ��λ���Ի�����������Ϸ�ֱ�ALPSҡ��Switchƻ��PC����Steam�� ԭ�� �ҵ����� ��Ұ쭳�9 ������³
- ȯ��ʡ3
-
��186.0
��189.0

- FIIL Key �������������� ͨ���ֻ����� ���ֶ��� ����5.3 ��ʯ��
- ȯ��ʡ10
-
��139.0
��149.0

- ����CMK99����/2.4G/������ģ���ƻ���е������Ϸ�칫�Ȳ��RGB�ƹ�TTC�������� ��ģFSA��ñ��-ȫ���ɻ���-������ TTC-�����V2
- ȯ��ʡ20
-
��799.0
��819.0

- ������HiVi�� M10 Plus 2.1������������ �ʼDZ�̨ʽ���ÿ��������������� ��Դ��ý��
- ȯ��ʡ25
-
��634.0
��659.0

- Ӣ�(crucial)MX500�ʼDZ�̨ʽ����ssd��̬Ӳ��sata3.0�ӿڸ��ٶ�д 480G-500G ��ȡ�ٶȸߴ�560MB/s MX500ϵ��/SATA3.0/3D������
- ȯ��ʡ15
-
��334.0
��349.0








