VMware Private AI���������ģ�VMware Private AI Foundation with NVIDIA��ʾ
 ���֣����룩
���ϱ༭������h
�����ڣ�2024-04-22 09:30
���֣����룩
���ϱ༭������h
�����ڣ�2024-04-22 09:30
|
���ı���ΪVMware�й�����ܹ�ʦ���֣�����2024��2��21��VMware by Broadcom �� Tech Field Day ��ֳ�AI Field Day 4�����ϵ���ݽ��������ݽ��α�ΪJustin Murray��Product Marketing Engineer, VMware By Broadcom��
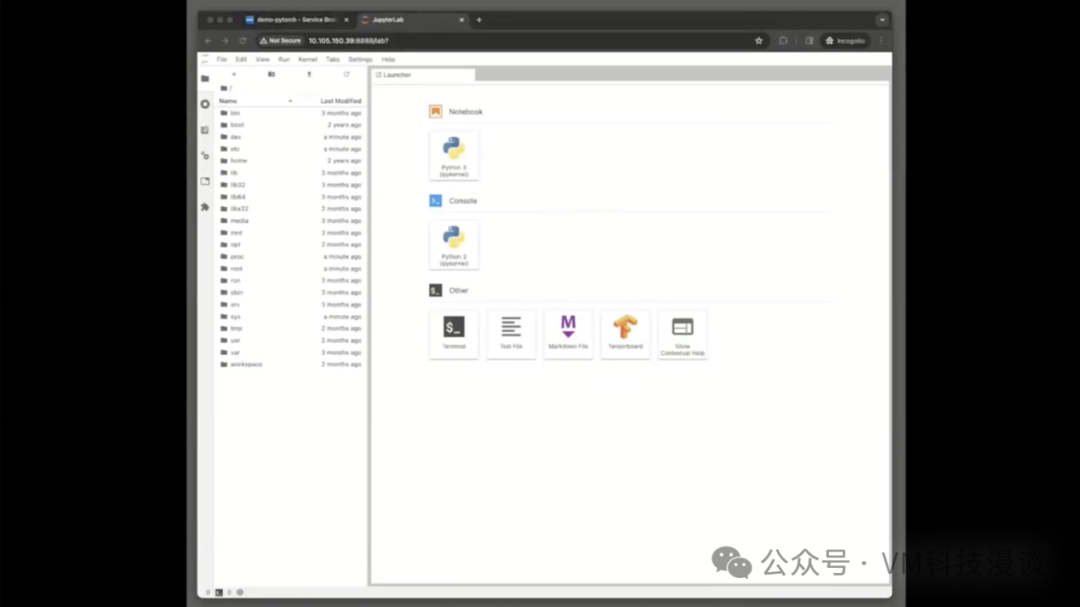
��ʾ���̸��� VMware Private AI Foundation with NVIDIA Ϊ���ݿ�ѧ���Լ�VMwareϵͳ����Ա/DevOps��Ա�ȵĹ����ṩ�������İ��������ݿ�ѧ�ҿ�����VMware Cloud Foundation (VCF)�Ͽ����������ǵ�LLM����������ͨ�����������Ż���VCFϵͳ����Ա��Э����ɵġ�������ʾ��ʾ��VCF����Ա������һ�������Ϊ���ݿ�ѧ���ṩ������Щ�������һ���µ��Զ�����ʽ�������ѧϰ�����ӳ��ģ���д����������Ѿ����������е����ѧϰ��صĹ��ߡ�����ʾ�������ն��û�(�ر������ݿ�ѧ��)��δӸý�����������档 -��ģ��AIӦ�ó�����ʾ������չʾ��һ���ɴ�����ģ��(LLM)���������������Ӧ�ã���ģ�������˼�����ǿ����(RAG)��������ʾ�������������֪ʶ������˿��Ը�ȷ�ػش����⡣ -���ѧϰ�������ʾ���ص������Ԥװ���ѧϰ���߰����������ʹ�ã���Щ���߰������ݿ�ѧ����˵������Ҫ����Щ���������ʹ��Aria Automation�������ã����ҿ��Ը������ݿ�ѧ�ҵ�����ʹ���ض��Ĺ��߰����ж��ơ� -�Զ������û�������ʾ����ʾ��Aria Automation�����������ݿ�ѧ�һ�DevOps��Աͨ���Ľ���������Դ����ѡ�������GPU������ -GPU�ɼ�����ʾ������ʾ���鿴��GPU�ɼ��ԣ�չʾ�����ʹ��vCenter���������������������GPU���ģ�����ڹ���LLM�����е���Դ����Ҫ�� �ݽ����� ����ʾ��չʾVMware Private AI Foundation with NVIDIA�ľ���ʹ�÷�ʽ��
����ʾ��һ��Ӧ�ó���ʼ��չʾ�ն��û������������ݣ��Լ����ݿ�ѧ��Ϊ��˾ҵ���û���������Ӧ�á�������һ������ǰ�����촰�ڵ�RAGӦ�ó����ţ��������˽�֧����һ�еĹ���ģ�飬�����ѧϰ�����������Ԥװ���������ݿ�ѧ������Ĺ��߰���Ȼ��ʹ��֮ǰ�ᵽ��Aria Automation�������Զ�����Щ��������ṩ���̡�������ǻ�����̽��GPU���ڲ������� �����ʾ�Ľ���������������������������ϡ�����Խ��������ΪKubernetes��Ⱥ�еĽڵ㣬����Щ�ڵ������а���������Pod������VMware�ϲ���Kubernetes��Ⱥʱ����������ܹ�����Pod�����������Pod�������ļ��ϡ������������������dz���Ȼ�ؽ����һ��NVIDIA�������Ϊ���������ģ����ǿ���ʹ��Docker��Ϊ�����������У�ͬʱ����Ҳ�������Էdz����ؼ��ɵ�Kubernetes�С� 1.��ģ��AIӦ�ó�����ʾ
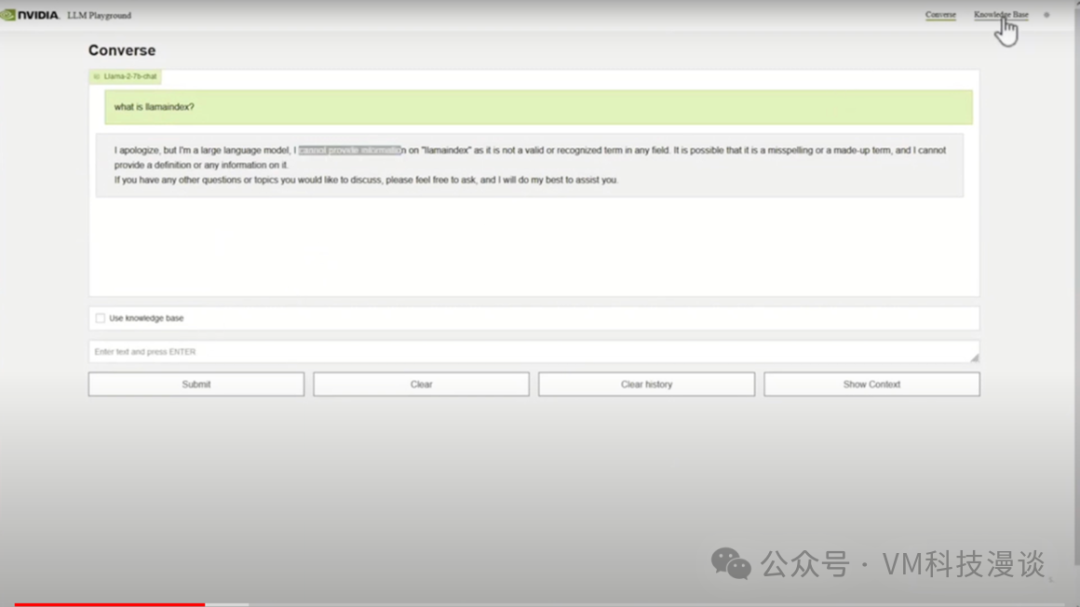
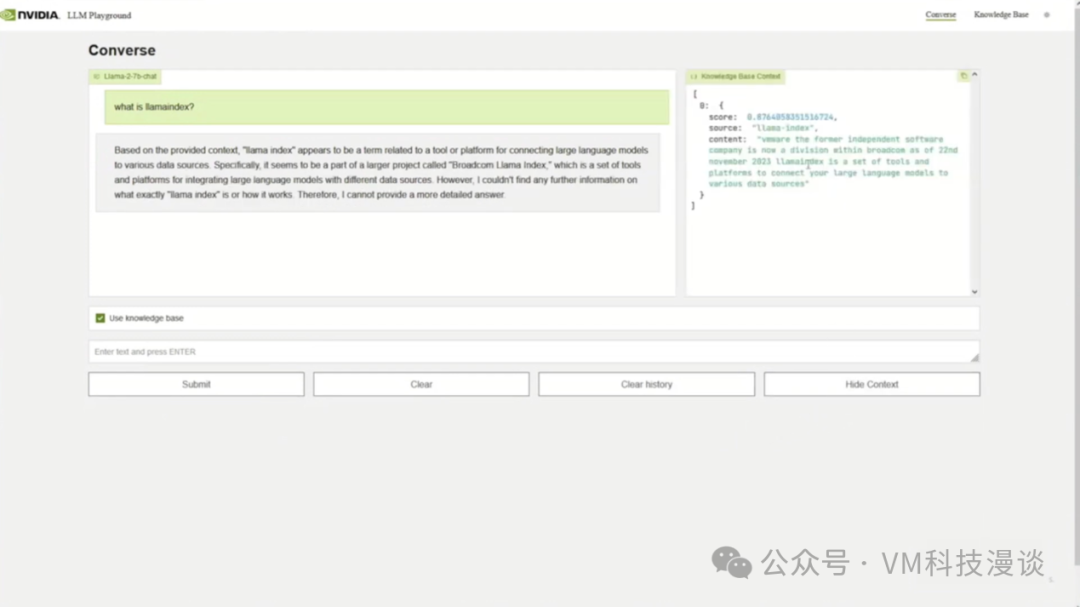
��ʾ�ĵ�һ��Ӧ�ó����������������ˡ���������ǽ�Llama-2 7bģ����ֲ���˿ͻ��ˣ���������һ���dz������������Ӧ�á�����ѯ���ˡ�LlamaIndex��ʲô?��������⡣�������ݿ�ѧ����LLM�����һ�����·�չ�������ģ��û�и����𰸣�����������������⡣��Щ֪ʶֻ����ģ���ⲿ���ܵ�֪�� Ϊ�˽��������⣬ͨ���ļ���ʸ�����ݿ����һ�����ݣ������������ݿ�LlamaIndexʵ������ʲô��Ȼ���ٴ�ѯ��ͬ�������⣬����δ���RAG���������ⲿ֪ʶ�⡣���ڵ��ٴ���ͬһģ���ύ��ͬ������ʱ���õ��Ĵ𰸸��������ˡ���˵LlamaIndex�����ڽ�������ģ�����ӵ�����Դ�Ĺ���ƽ̨��
���ڶ������Դ�����⣬LlamaIndex����һ�����ӡ����Ǵ��ṩ��ģ�͵��������ݿ��м���������Ϣ��ģ�ͻ��ڴ˵����˴𰸣�ʹ����������⡣
���⣬NVIDIAΪ�û��ṩ���ڶ�Դ����ʾ������Щʾ�������ݿ�ѧ�ҿ��Բο���RAGӦ�ã�������������������ǿ���ɻ������ģ�͵���Ŀ�����ǽ���Private AIһͬ�ṩ��ЩԴ���룬��������Ӧ�������� ����ʱ�����ޣ�������ʾ������������Դ���롣������NVIDIA��VMware�����ݿ�ѧ����Ϊ�û����������ɫ��ʾ�����û����Դ��п�ʼ̽�������磬ʹ��TensorRT�����Ż�����ģ�ʹ�16λ����Ϊ8λ��������Щ��������ԽϾɵġ�װ��������GPU�ķ����������еġ���Щ������ʹ�õ���A100 40G���Ѿ����������ˡ�
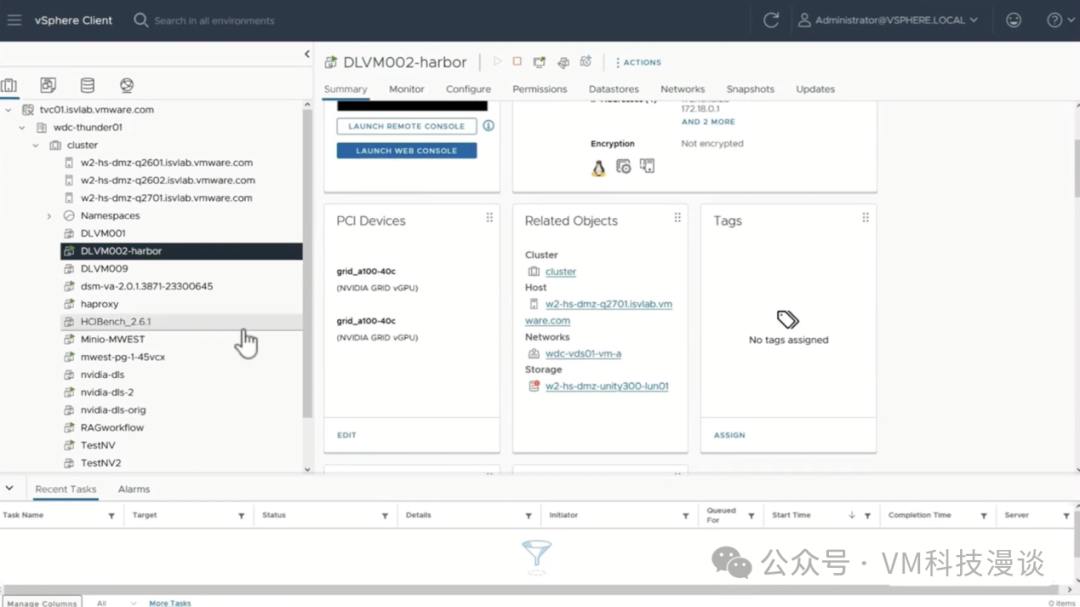
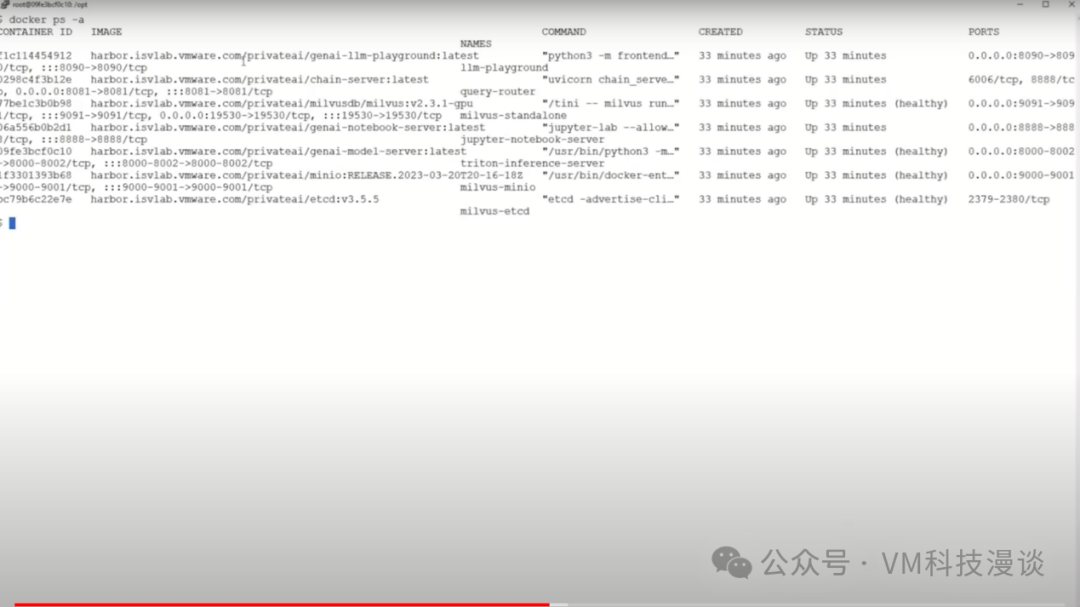
2.���ѧϰ�������ʾ ���Կ����ض������DLVM002-harbor�ϸ���������A100.������һ��С���ɣ�������VM�ϸ��Ӷ��GPU������VMʹ����ЩGPU������ʾ��������Щ��������GPU������GPU��NVIDIA��VMware�����Ƴ��ĸ���������û�����������ƶ������������е��κ�λ�ã���ʹ��GPU���ӵ����С���Ҳ��VMware���û�������ȡ��������
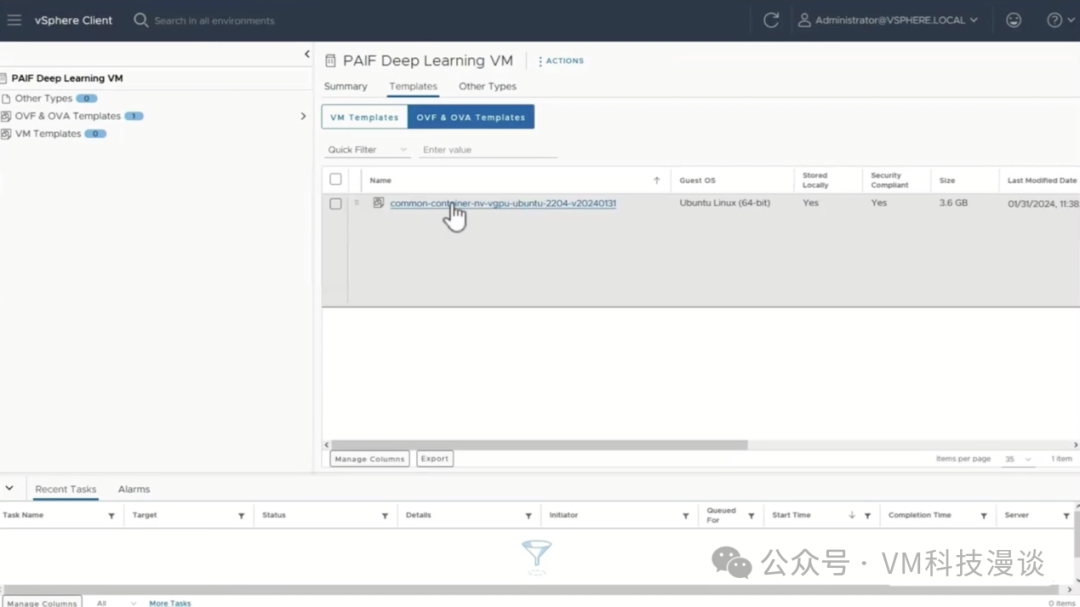
���VM�ǻ��ڴӹ����Ŷ����صľ����ģ������������Content Library�С�Content Library�Ǵ洢���������ĵط�����VMware Cloud Foundation�У���ʾ�õ�Content Library��Ϊ��PAIF Deep Learning VM�����ڸÿ��У����Կ���һ��OVA������������VM�Ļ���ģ�塣��ˣ���ΪPrivate AI Foundation��һ���֣�����ӵ�����ѧϰVM��ģ�壬���Դ���һϵ�����ò�ͬ���ݵ�VM��
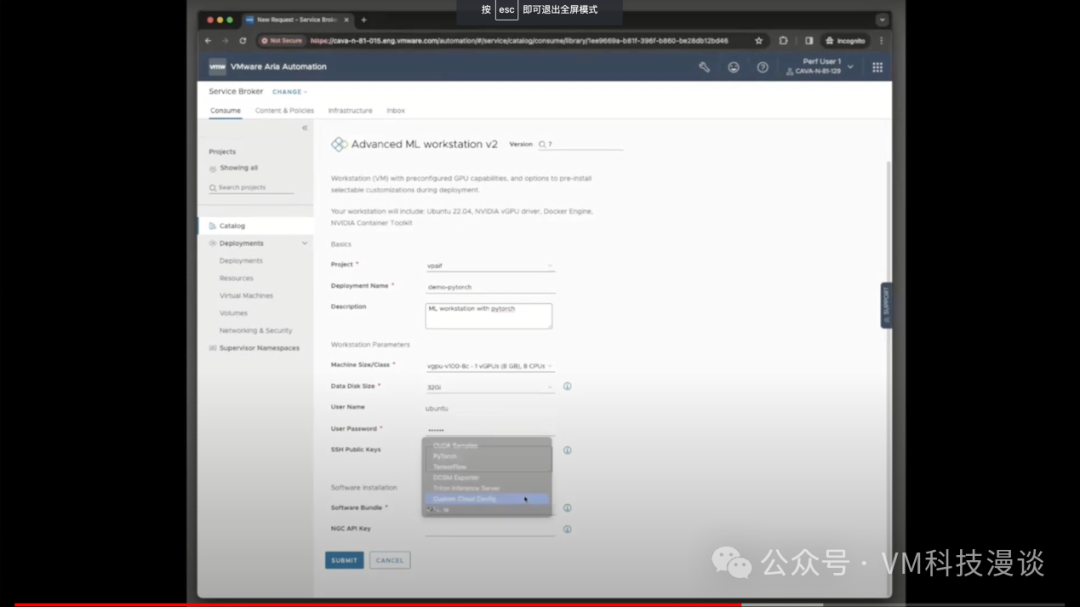
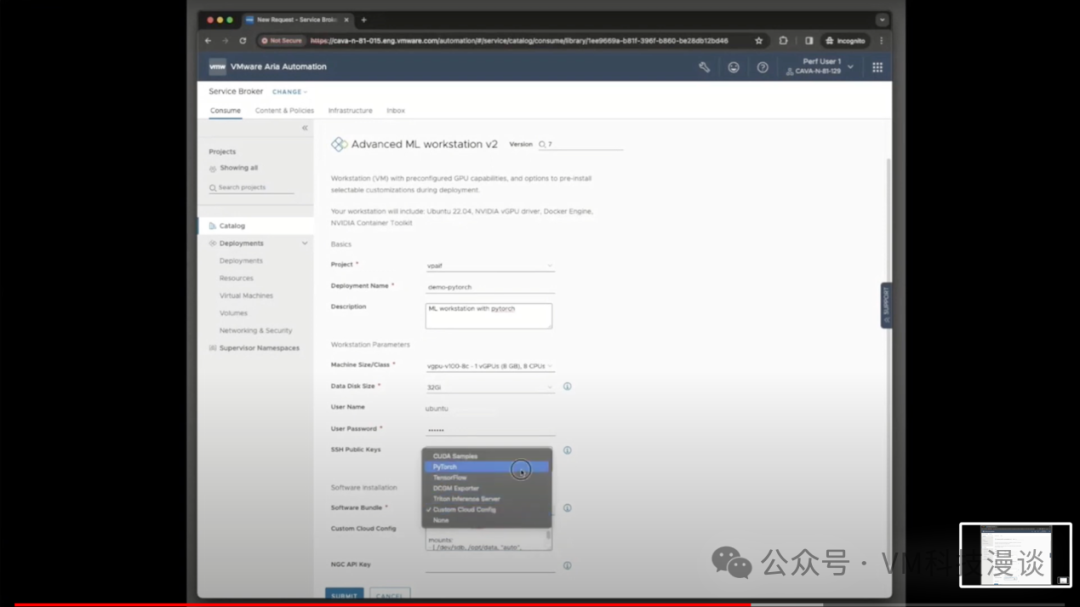
���ѧϰVM���������Ԥ�Ȱ�װ��������NVIDIA��AI���ߣ�����TensorFlow��PyTorch���ʵ����߰�����������ʾ��ʱ����Ҫʵʱ��NVIDIAȥ���أ�ֻ��Ҫ�������Ǽ��ɡ� Ŀǰ���Ѿ���һЩ���ڿͻ�ͨ������ʹ���ƻ������������������ʹ�û���VMware Cloud Foundation��NVIDIA AI Enterprise�Ļ����ܹ���VMware����Щ�ͻ��Ѿ������˶���ĺ�����ϵ��Ϊ�����ṩ���ȶ�����������֧�֡����µ�LLM��ع�������VMware��Ʒ�Ķ���֮���� �ڿ����������棬��Ȼ���������������Ҫ������ʱ�䣬��VMware������������������ʽ��������һ������Ray��Ⱥ���������������Ray��һ���㷺ʹ�õ�ƽ̨��ͨ�������ʹ�����ӿ�¡���͵IJ�����÷dz����٣�ֻ��Ҫ�����ӵ�ʱ�䡣 ��Ȼ��ʾչʾ����һ����̬�ļ����û������ϴ��Լ����ĵ������÷���Ҳ���Դ�����ʽ�ĵ��������ϵ��ṩ�ĵ��������ģ�ͳ������¡�������ƽ̨�У�����NeMo���ڣ�����ר�ŵ�API������ʽ�������û�����ͬʱ������������������������Ӧ����Ϊһϵ����������ǵ���������ء�
�����ѧϰVM�в鿴һ�£���ʵ�dz�����ֻ��һ�����Docker������������Щ��������һЩ����֮����˳��һ�ᣬ����Milvus�������ݿ⣬���ܻش��û����ڿ�Դ���ݿ�����⣬����ʾ���ÿ���ʹ����������ʾʹ����NVIDIA�ṩ�����ݣ����а�����һ����Դ���������ݿ⣬�ڴ˴�ֱ��ѡ�������С�
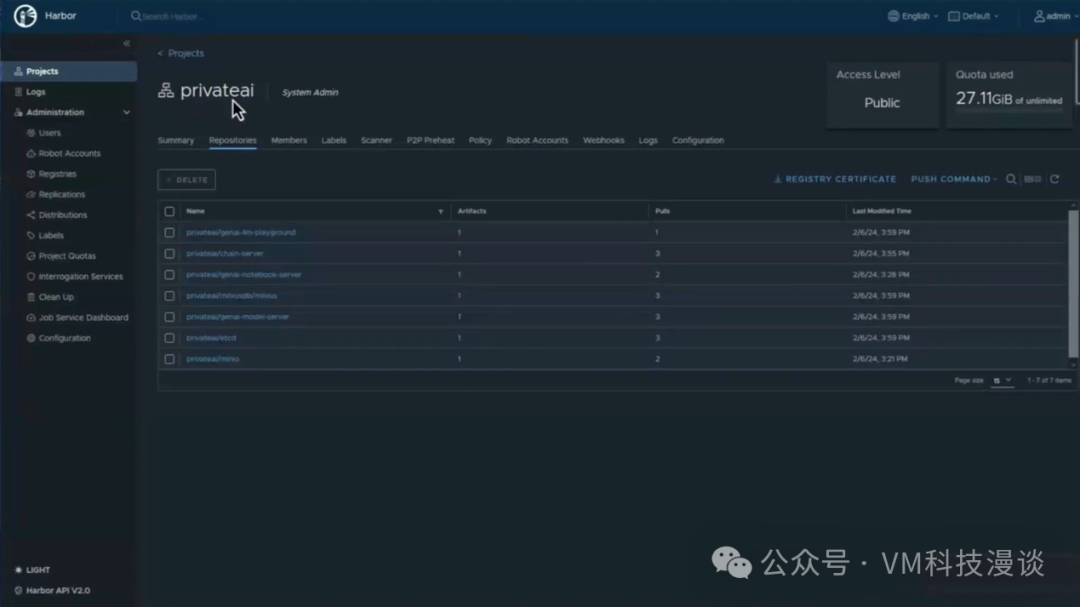
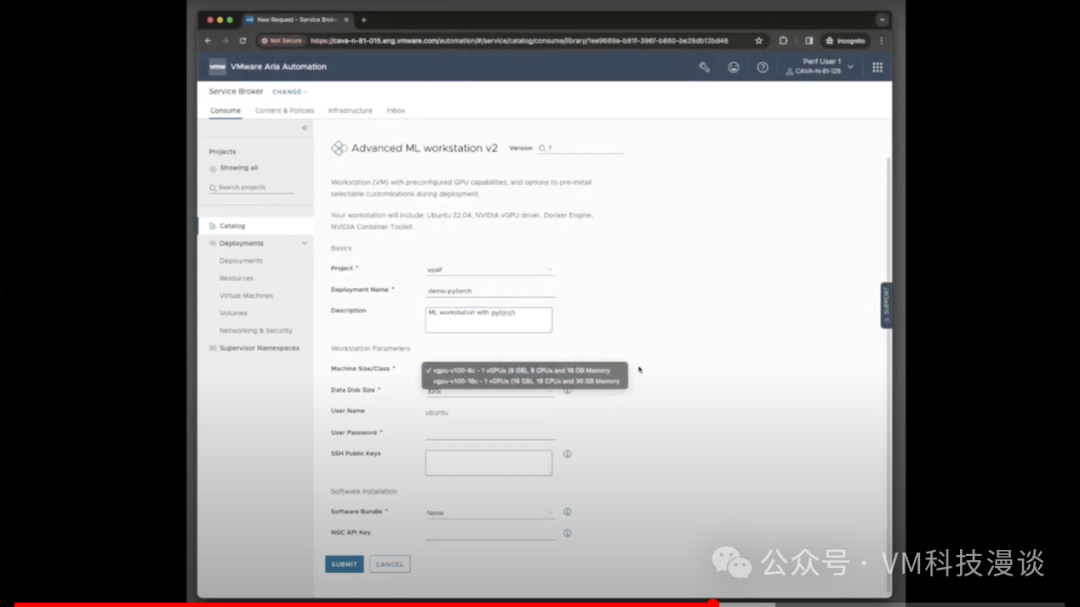
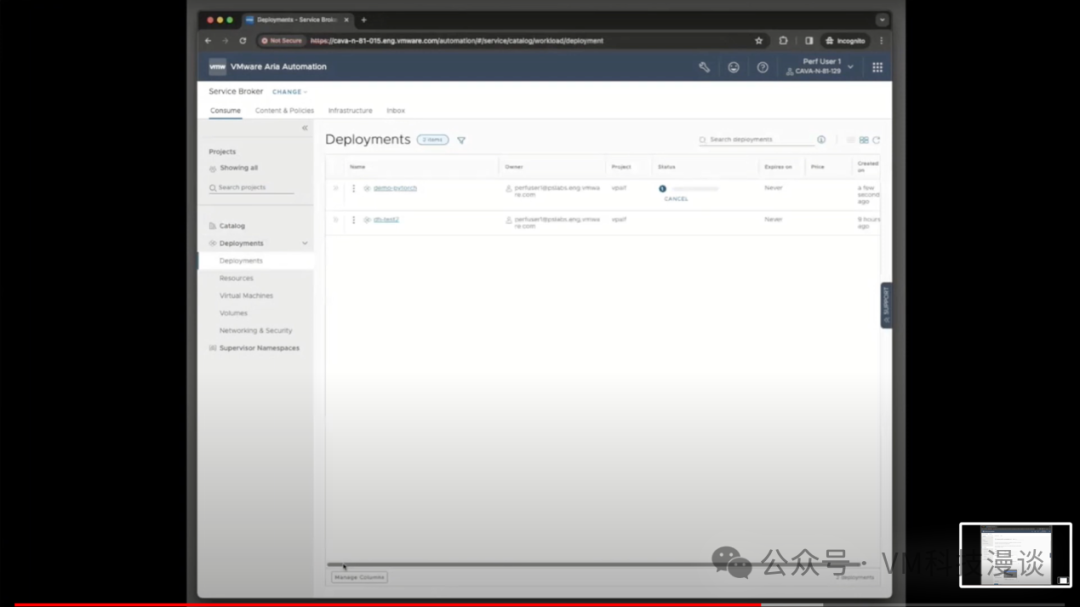
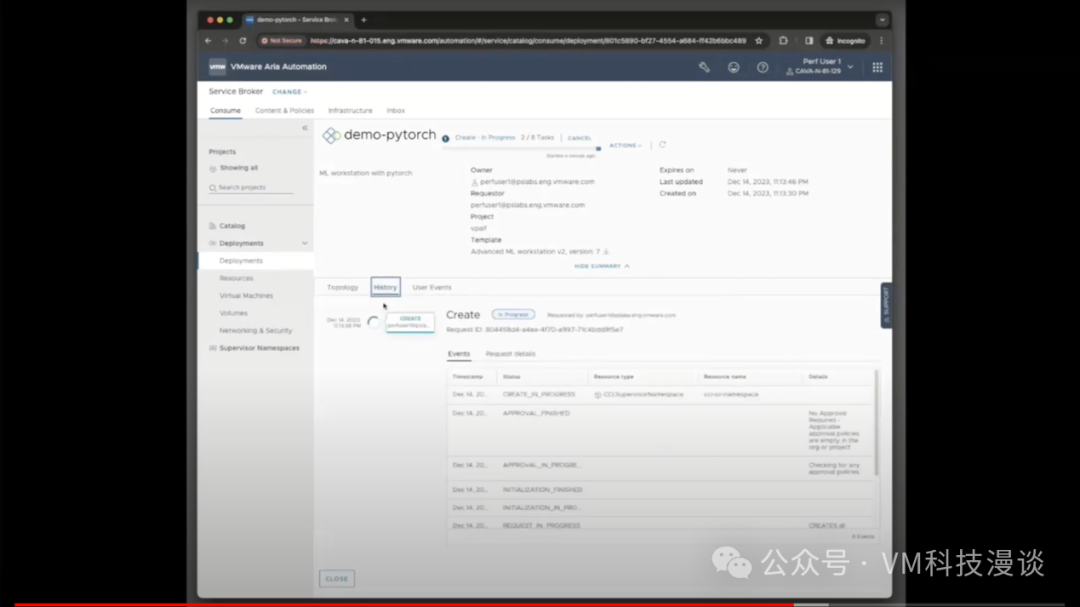
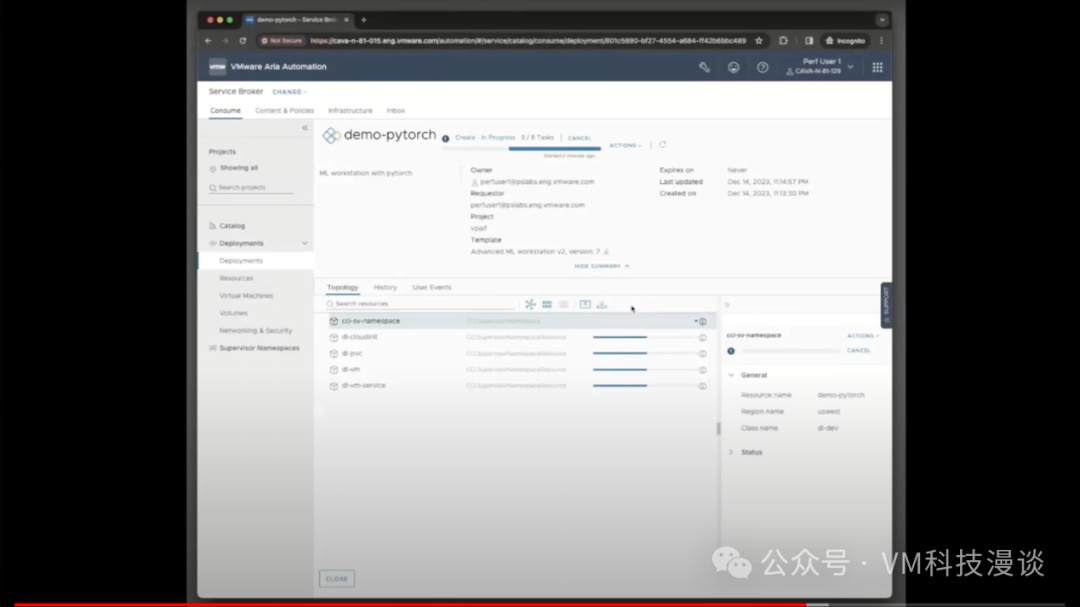
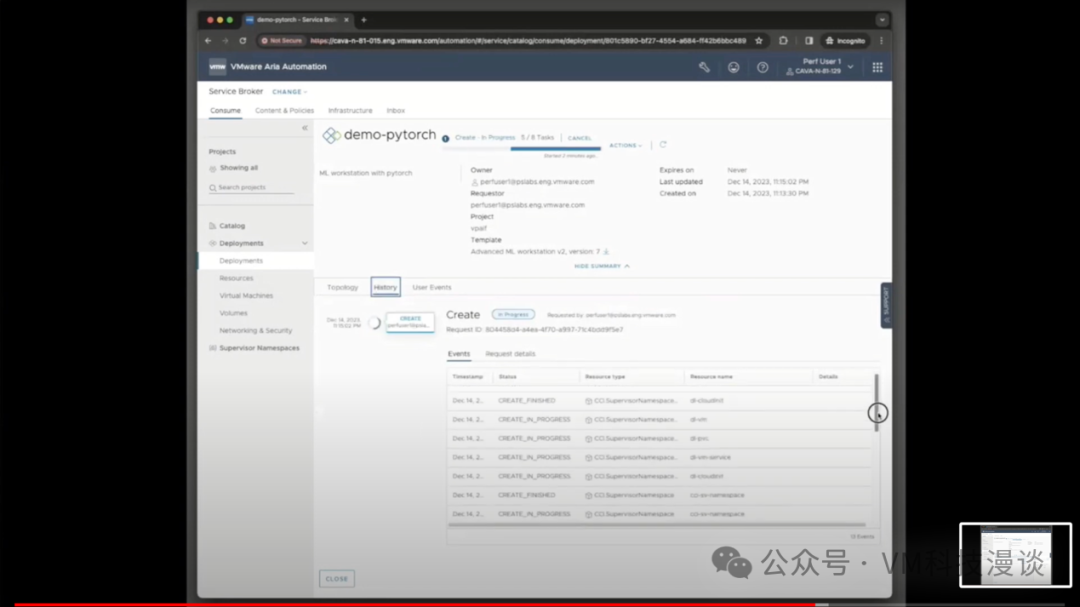
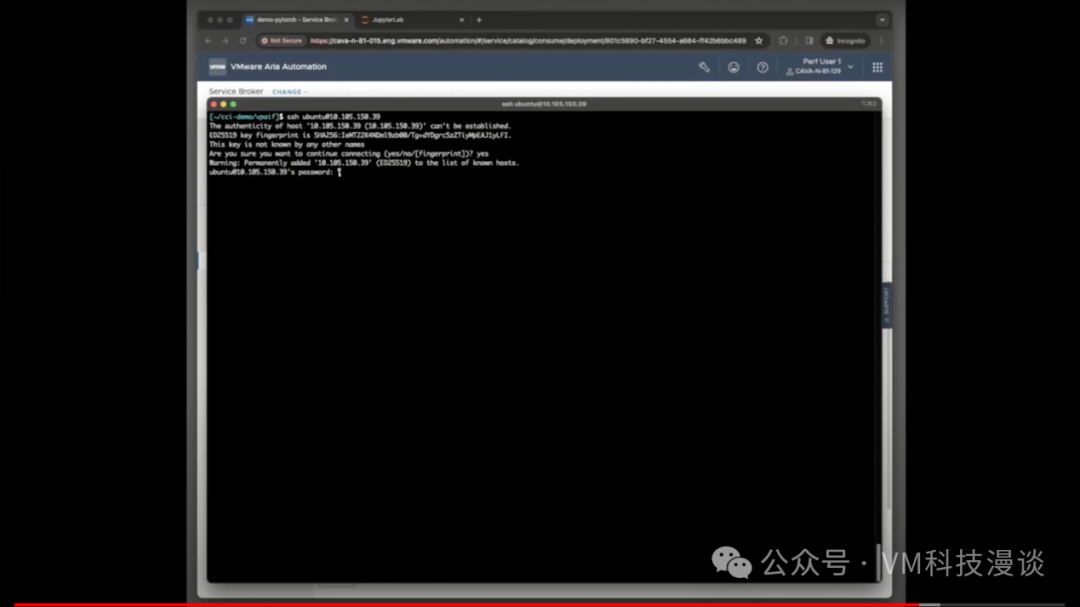
��������ض��ı�ǩ��harbor.isvlab.vmware.com������ָ������ǰ�������ڲ�Harbor�洢�⡣���Harbor�洢����һ����������Ĵ洢�⣬�����ṩ��˽���ϡ���Ϊ����ζ�Ų���Ҫ��NVIDIA�Ĺ����洢������ȡ������Ҳ����ͨ����������ȡ�� ����ʾ��������ⲿ�ֳɵ����µĵ����ܲ�̫��ȫ���������෴��ʹ�õ��Ǿ������Ժ���֤���ض���������ȷ�������������Ĺ���ԭ������Щ��������������ʾ��ʵ��������������ʾ�Ĵ洢���У���˾���˽���ԡ��ɴˣ����Դ��л���������ƣ����ȣ������������ڱ��أ���������ٶȸ���;��Σ��������ȫ����˽��������Ϊ��Щ����NVIDIA������˽�а汾�� ��Ȼ��������ʵ�û�������˵�����ϣ�������ⲿ���ݣ���ȫ����ѡ���µ�����Դ����ʵ�ϣ�������ģ�������������ĸ��Llama 2ģ�͵�������Դ��Meta��������Ƚ��������һ����ȫ�ĵط������˲��ԣ�Ȼ�����ϴ�������ʾ�õĵı���HTTP�������ϣ�����������������Ϳ��Դ������ȡģ�͡���ˣ��������̱�ø���������ʵ���������������Ǹ�ѧ���о�ʾ���� 3.�Զ������û�������ʾ ���ڣ����������ʾʵ���������̵��Զ�����Ϊ�˽�ʹ���Զ�������Aria Automation�� ������ȴ�����һ������������֮ǰչʾ������������һ�����ݿ�ѧ���ڴ����Ϸ��������ʾ�����⽫�����ݿ�ѧ�ҿ�����Ψһҳ�棬������������ע������ʩ���⣬ֻ��ͨ���ķ�ʽ�������軷�����ɡ�
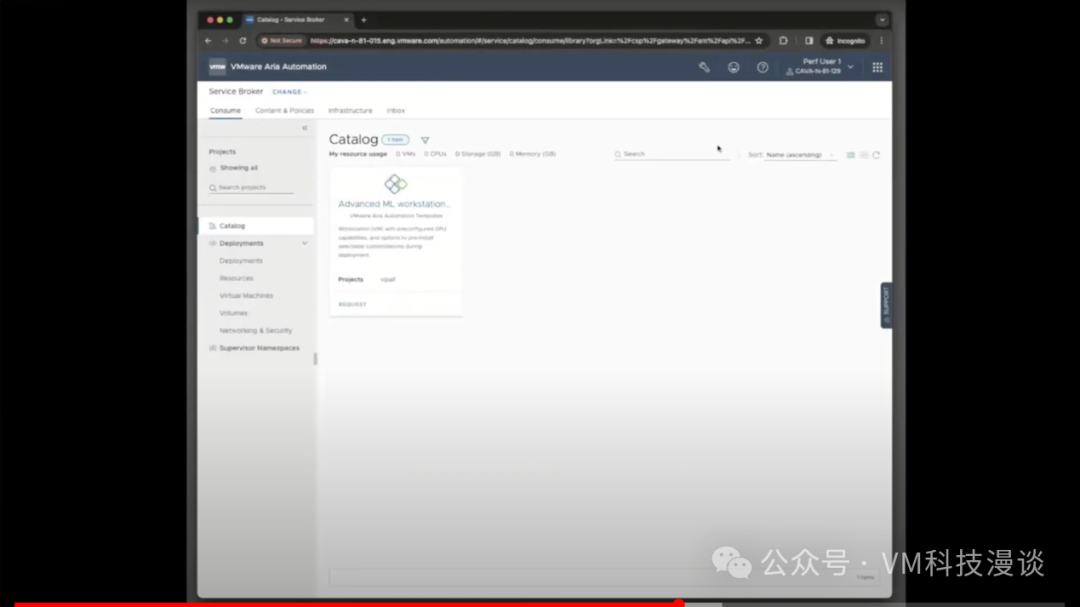
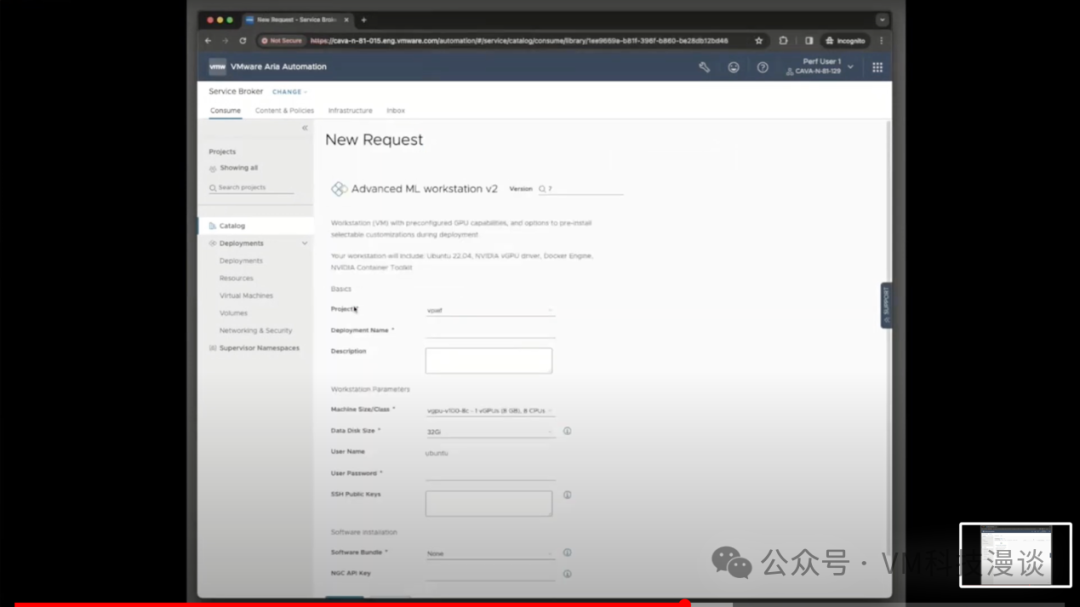
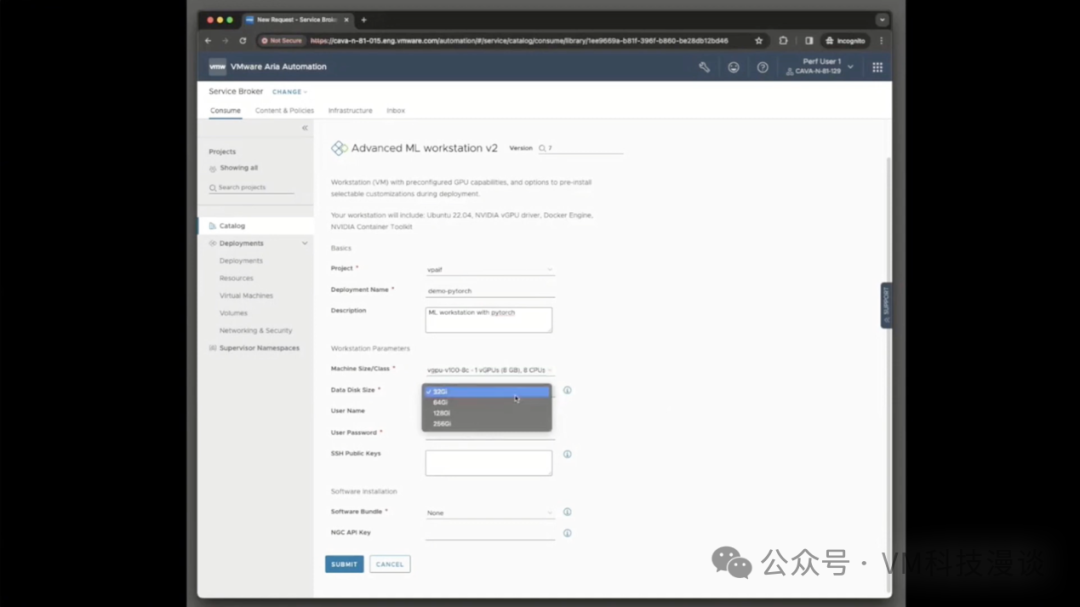
��֮ǰ��˵���������ݿ�ѧ�ҿ���ʹ��������ߣ�DevOps��Ա��ƽ̨����ʦ��Ҳ���ԡ�������Ҫ���Ĺؼ������Ƿ������GPU��������������������У�����������ѡ��8GB��16GB��GPU������������������ǿ���ʹ�õ�ȫ�����ݡ���Ȼ�����Ը�����Ҫ���������Χ��
ͨ���ṩ�û�ID�����룬���ݿ�ѧ�ҿ���ѡ��ʹ���Լ��Ĺ��߰��������dz����ṩ�ġ�����ֻ������Ļ�ײ�������ύ����ť��������Ȼ��Ϳ��Եȴ��ˡ����������ٽ����κβ�����ϵͳ��Ϊ����������еײ�����������á���Ȼ���������Ҫ����3���ӣ�����Լ5�������ң����ݿ�ѧ�ҾͿ��Կ�ʼʹ���ˡ�
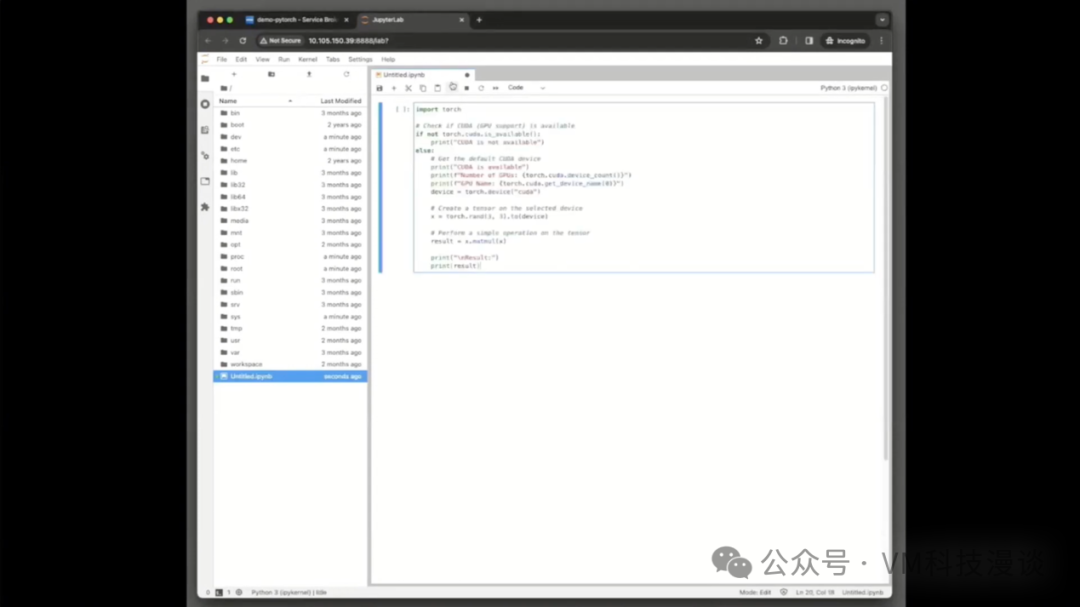
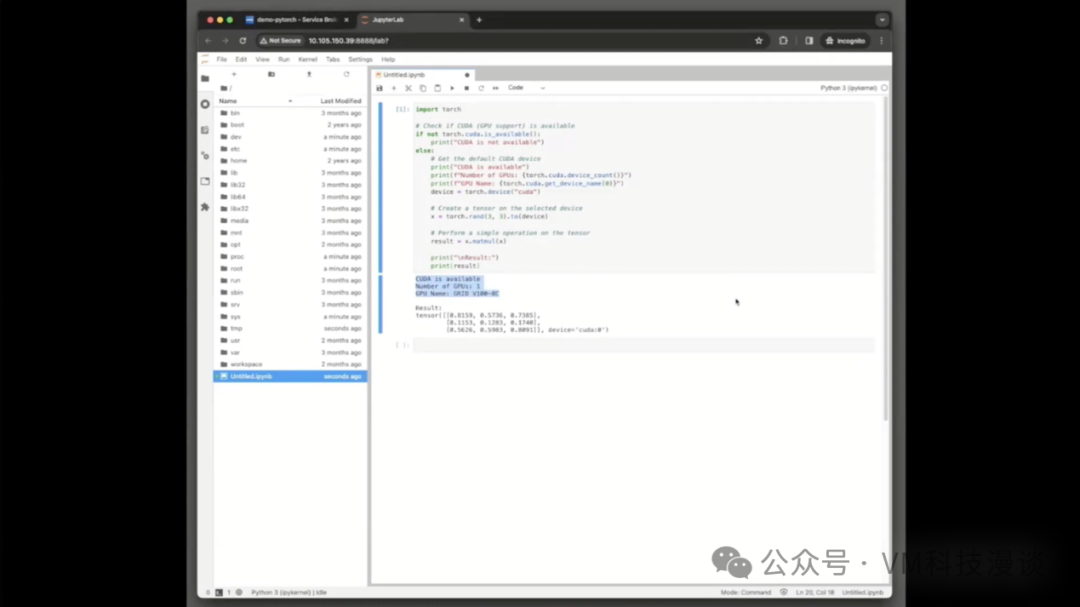
���ݿ�ѧ��Ҳ����ͨ����д�ű��ķ�ʽ��ȷ��������˳�����У����Զ�ִ����ز�������Ȼ����ʾ��δ�漰������һ���̵IJ��֣�������δ����������������������û������Service Broker�ϡ������ⱳ������һ���Ľű�����֧�ֵģ�����Щ�ű�ȷʵ���������������Զ������̡����⣬���ݿ�ѧ�������û���ʱҲ����������Aria Automation�ṩ��һ��ͼ���û����棬ר�����ڹ�����Щ���ݡ� �������һ���������̵����ս�����ж��ַ�ʽ���Խ�����ʾ��������ͨ��������Jupyter Lab��������ͨ��SSH����������Բ鿴�ڲ���������ȡ��������ֻ��ʾJupyter Lab���֣���Ϊ�������Ǵ�������ݿ�ѧ�������Ȥ�IJ��֡� �����ʾʾ���dz�����ʹ����PyTorch����⣬ԭʼ��Torch�ⱻPython���ɲ�����ΪPyTorch������Ĵ���Ƭ�����ڼ��CUDA��GPU�Ƿ��������У����������˷��Ľ�����ڴ�����ģ���ڲ������־���˷������dz������еġ����ݿ�ѧ�ҿ���ͨ��SSH�������ǵ���������鿴����ϸ�����������
��ʵ���ն��û������У�ʹ�������������Ϊ���ݿ�ѧ�Ҳ���ģ�ͣ��Լ�����Notebook���ܵIJ�����ǿ���������ơ�Notebook as Service������K8s�����У������ֻ�����������ڡ�
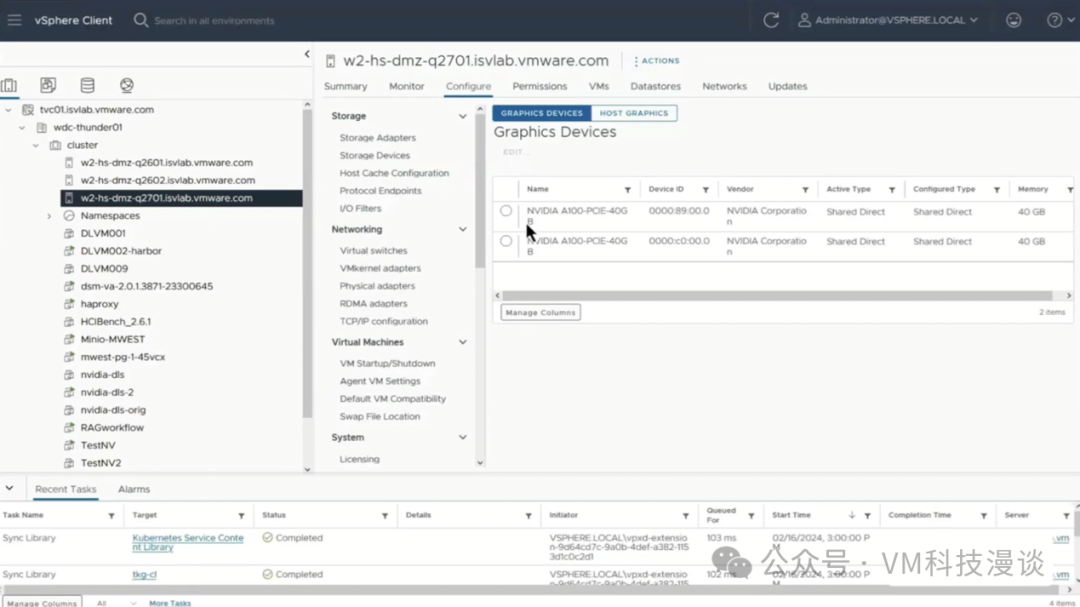
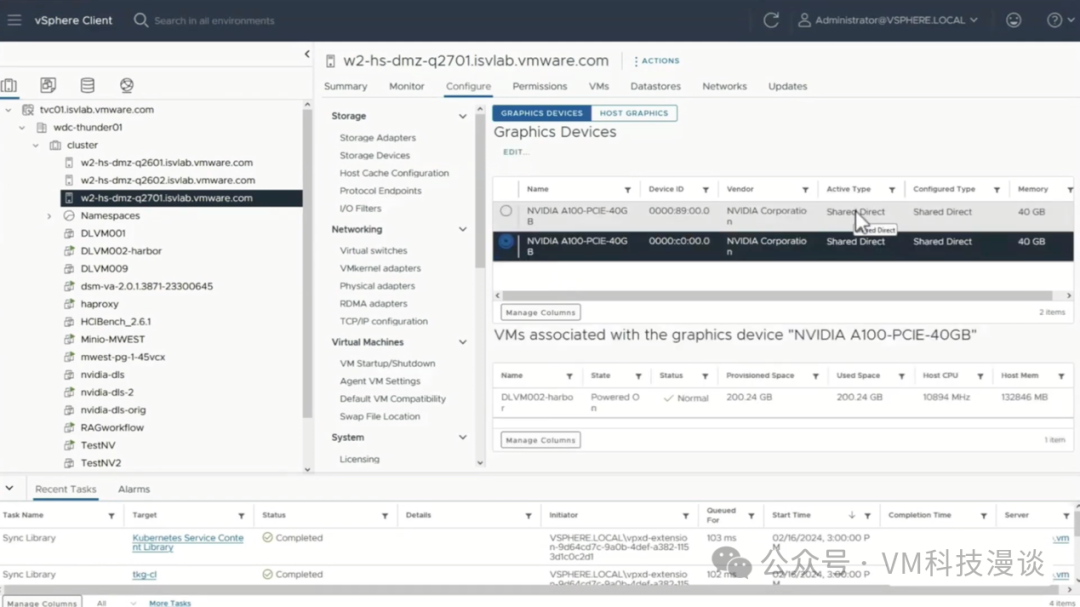
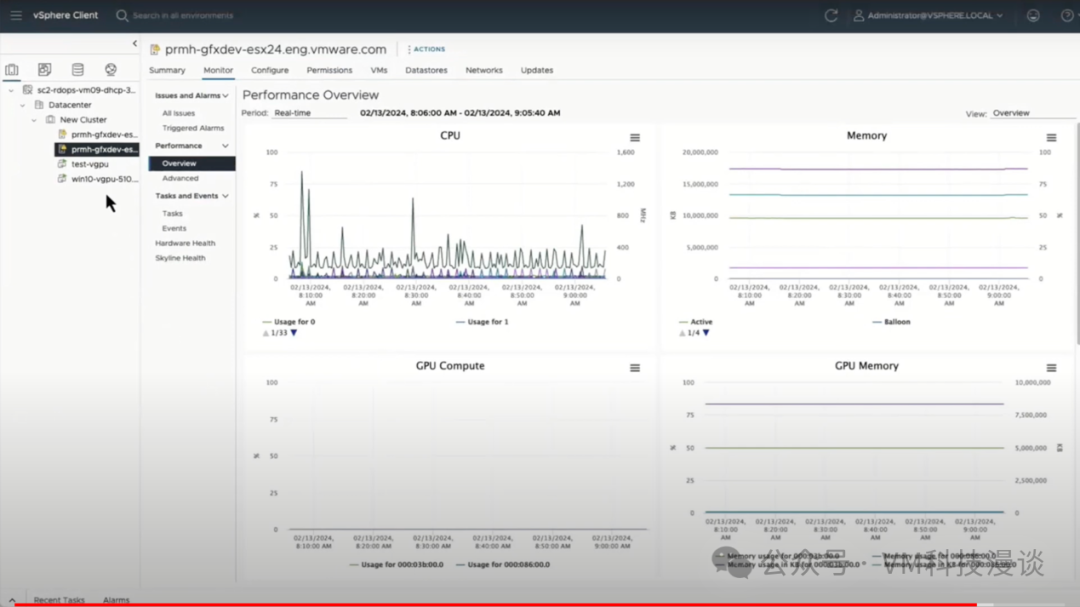
4. GPU�ɼ�����ʾ ������������GPU�ɼ��ԡ���֮ǰ���ἰ�ģ��ڴ�����ģ���У�˭��ʹ��GPU�Լ��������ʹ��GPU���������Ҫ����Ϊ�����������GPU���������������ģ�Ͳ����Ƿdz������ġ�
����������ṩ��������Ŀɼ��ԣ������ͻ����ʾ����������Ϣ�����������ṩ���������Ŀɼ��ԡ���ˣ��û����Բ鿴GPU������������������ڲ��ĺ��ĺ��ڴ档��vCenter�û������У��û�������ϸ�˽�ÿ��GPU������� ͨ������ij��ԭ��ʹ��GPU���˶��Թ��ĺܸ���Ȥ�����û���㹻�ĵ�����Դ������GPU��Դ�������ܺõ����õģ�������GPU����ϡȱ��Դ����Ҳ����Ҫ�и��õ�GPU�Ŀɼ��Ե���Ҫԭ��֮һ�� ������ʾ�������ȫ�������ˡ���Ҫ�ع�һ�£���ʾ��չʾ��AIӦ�ó������ѧϰ�������ʹ��Aria Automation�������ݿ�ѧ�һ�DevOps����ʦ�Ĺ������̡����������GPU��Ϊ�ײ������ʩ�����Ŀɼ��ԡ� VMware AI������������Ϣ���� Artificial Intelligence Solutions | VMware AI (https://www.vmware.com/artificial-intelligence.html) VMware's Approach to Private AI (https://news.vmware.com/technologies/vmware-technology-private-ai ) Deploying Enterprise-Ready Generative AI on VMware Private AI (https://core.vmware.com/resource/deploying-enterprise-ready-generative-ai-vmware-vmware-cloud-foundation ) |




ԭ����Ŀ

 Ӳ������ʷ
Ӳ������ʷ


��ҵ��Ƶ

IT�ٿ�

��������
�۳�ֵ•��ѡ
-

- ���루Lenovo��������Y7000P 2024 14�����i7 16Ӣ��羺��Ϸ�ʼDZ�����(i7-14650HX 16G 1T RTX4060 2.5K��ˢ)
- ȯ��ʡ10
-
��15989.0
��15999.0

- �ȿ���Pkcell���������̼�Ի�������5��20��+7��20������40����ң��/���ӳ�/��� ̼��20��5��+20��7��
- ȯ��ʡ68
-
��52.9
��120.9

- ��ʣ�DeLUX��M800Pro �����Ϸ�����������������ģ���羺���PAW3395������������ M800pro��3395����ɫ
- ȯ��ʡ40
-
��159.0
��199.0

- �������� K3����˫ģ����е���� �Ѵ�¡2.0��е���� 84��������� Mac/iPad���� ���ᱡ��Я�칫
- ȯ��ʡ20
-
��339.0
��359.0

- ���루Lenovo��4TB SSD��̬Ӳ��m.2�ӿ�(NVMeЭ��)PCIe4.0 x4 ������sl7000 40Pro���ٸߴ�7100MB/s
- ȯ��ʡ10
-
��1989.0
��1999.0
-

- Apple/ƻ�� Watch Series 9 �����ֱ�GPS+���ѿ�45����ʯīɫ����ֱ���ʯīɫ������˹���� MRPQ3CH/A
- ȯ��ʡ300
-
��6299.0
��6599.0

- Apple/ƻ�� Watch Series 9 �����ֱ�GPS��41����ɫ���������� ��ɫ�˶��ͱ���M/L MRXH3CH/A
- ȯ��ʡ300
-
��2699.0
��2999.0

- ���ߣ�Razer�� ��������V3proרҵ������2.4G�������羺��Ϸ��� ���幤ѧ�ʼDZ����ԳԼ���� ����Լ64�� ���� ������V3רҵ�� ��
- ȯ��ʡ70
-
��829.0
��899.0

- Apple/ƻ���������Żݡ� iPad Air 10.9Ӣ��ƽ����� 2022��(64G WLAN��/MM9D3CH/A)��ɫ
- ȯ��ʡ200
-
��4199.0
��4399.0

- ��ҫ100 Pro ���������� ��ҫ�������� �ڶ�������8�콢оƬ ������˫������ OIS 12+256 Ī���� 5G
- ȯ��ʡ20
-
��3279.0
��3299.0
-

- AOC U27V5C 27Ӣ�� 4K��ʾ�� IPS��ɫ�� 65WType-C �������� �������� ��ת���� ������ʾ��
- ȯ��ʡ10
-
��2189.0
��2199.0

- VGN N75��Ϸ�������ƻ���е����gasket�ṹ75%����ȫ���Ȳ��
- ȯ��ʡ50
-
��139.0
��189.0

- �������ݣ�WD��4TB �ƶ�Ӳ�� type-c My Passport Ultra 2.5Ӣ�� �� ��еӲ�� ������ �ֻ�������� ���ܼ���Mac
- ȯ��ʡ20
-
��939.0
��959.0

- ֥���ڴ����ʼ��32g̨ʽ��DDR4 16g 3200 3600 4000�ù������
- ȯ��ʡ20
-
��729.0
��749.0

- ���û�ΪP60proP30/P40/P50�ֻ�Ĥmate60/30/40/50nova6/7/8/10/11/12��ҫ90/70/80ˮ��x50�ֻ�8x9x��Ĥx40
- ȯ��ʡ1.6
-
��7.2
��11.8
-

- ��ҫMagic Vs2 ���ᱡ���� ����յ��⻤��˫�� 5000mAh�������� 5G �۵����ֻ� 12GB+256GB ��ɫ
- ȯ��ʡ20
-
��6979.0
��6999.0

- С��ŵ绰�ֱ�Q2A �����⾫��λ��Ƶͨ����������ͯ��Ů��������� Q2A ���Ʒ�
- ȯ��ʡ100
-
��499.0
��599.0

- �ȿ���Pkcell�� �ȿ��ߺŵ������̼�Ի������á�5��20��+7��20����40����/���ӳ�/�� ̼��20��5��+20��7��
- ȯ��ʡ68
-
��52.9
��120.9

- RKR98���ƻ���е��������������ģRGBȫ�����GASKET�ṹ�羺��Ϸ
- ȯ��ʡ50
-
��149.0
��249.0

- �������� ���Բʺ��� 5��40��װ ��������Ǧ�� ����Ѫѹ��/Ѫ����/ָ����/ң����/���ӳ�/��ͯ���
- ȯ��ʡ5
-
��34.99
��40.0







